All in One View
Content from Getting Started
Last updated on 2025-08-25 | Edit this page
Overview
Questions
- Was bedeutet die Digitalisierung für die Geisteswissenschaften?
- Wie verändert die Digitalisierung die Geisteswissenschaften?
Objectives
Nach Abschluss dieser Einheit sollten die Teilnehmenden in der Lage sein,
- eine grundlegende Erklärung der theoretischen und methodischen Implikationen der Arbeit mit Daten zu geben.
Einführung
Die Digitalisierung beeinflusst die Geisteswissenschaften grundlegend, indem sie die Art und Weise verändert, wie Wissen erzeugt, zugänglich gemacht und interpretiert wird. Heute wird nahezu alles in Daten übersetzt und durch Prozesse wie Digitalisierung, Visualisierung und Veröffentlichung miteinander vernetzt. Kultur und Geschichte treten zunehmend in vernetzten Formen hervor – ein Wandel, der durch digitale Technologien erheblich vorangetrieben wird. In diesem Kontext nehmen Daten und Metadaten eine zentrale Rolle ein. Diese Lektion dient als Einführung in die Bedeutung von Daten und Metadaten in den Geisteswissenschaften. Die Teilnehmenden werden mit den grundlegenden Konzepten von Daten und Metadaten sowie mit Formaten wie XML und JSON sowie gängigen Metadatenstandards vertraut gemacht.
Exploratory Questions
Überlege:
- Woher beziehst du deine Informationen?
- Wie verfasst du deine Texte?
- Wie pflegst du deine Kontakte zu Institutionen, sowohl im akademischen als auch im beruflichen Bereich?
- Nutzt du eher Papierkopien von Archivdokumenten oder digitale Fotografien davon?
- Hast du schon einmal ein Archiv persönlich besucht, um vor Ort zu recherchieren?
- Hast du schon einmal die Website eines Museums oder einer Bibliothek genutzt, um digitale Ressourcen zu recherchieren?
Reflektiere, wie sehr Digitalität inzwischen verschiedene Bereiche deiner beruflichen und privaten Lebenswelt durchdringt – und wie viel davon sich bereits ganz selbstverständlich anfühlt.
Challenge
Reflektiere das letzte Thema, an dem du gearbeitet hast. Suche nach Online-Ressourcen, die deine Forschung unterstützen oder dein Verständnis vertiefen könnten. Mit welchen Herausforderungen warst du bei der Recherche oder Interpretation online verfügbarer Informationen konfrontiert?
Die Digitalisierung beeinflusst die Geisteswissenschaften grundlegend, indem sie die Art und Weise verändert, wie Wissen erzeugt, zugänglich gemacht und interpretiert wird. Heute wird nahezu alles in Daten übersetzt und durch Prozesse wie Digitalisierung, Visualisierung und Veröffentlichung miteinander vernetzt. Kultur und Geschichte treten zunehmend in vernetzten Formen hervor – ein Wandel, der durch digitale Technologien erheblich vorangetrieben wird.
In diesem Zusammenhang spielen Daten und Metadaten eine wichtige Rolle. Daten sind unverarbeitete Informationen wie Texte, Bilder oder Einträge in einer Datenbank. Metadaten liefern den Kontext – also Beschreibungen, Schlagworte oder Informationen darüber, wie und wann die Daten entstanden sind.
Die Digitalisierung beginnt mit der Umwandlung von Inhalten in Daten. Ganz gleich, ob es sich um Texte, Bilder oder Töne handelt – all diese Inhalte werden in digitaler Form als Daten gespeichert. Damit diese Daten sinnvoll genutzt, gefunden und verstanden werden können, müssen sie beschrieben und geordnet werden. Genau hier kommen Metadaten ins Spiel: Sie liefern Informationen über die Daten – etwa darüber, was sie darstellen, wann sie entstanden sind oder wie sie verwendet werden können.
Beim Arbeiten mit digitalen Ressourcen sind sowohl Daten als auch Metadaten entscheidend – sie ermöglichen es, Informationen zu ordnen, gezielt zu suchen und sinnvoll zu interpretieren. Die Herausforderungen, denen ihr bei Online-Recherchen begegnet, spiegeln die Komplexität im Umgang mit diesen Elementen wider. Dazu zählen unter anderem die Sicherstellung der Genauigkeit, der Erhalt des Kontexts sowie der Umgang mit großen Informationsmengen.
Bevor wir in den praktischen Teil der Lerneinheit übergehen, wollen wir kurz besprechen, in welchen Bereichen die Digitalisierung für die Geisteswissenschaften eine zentrale Rolle spielt.
1. Transformation der Forschungsmethoden
Digitale Werkzeuge ermöglichen es Forschenden, mit großen Datenmengen zu arbeiten, etwa mit eingescannten Texten, Bildern oder historischen Dokumenten. Techniken wie Text-Mining, Mustererkennung und Datenvisualisierung helfen dabei, neue Erkenntnisse zu gewinnen, die mit traditionellen Methoden nur schwer zu erreichen sind. Macht euch keine Sorgen, wenn Ihnen diese Methoden noch nicht vertraut sind – das Verständnis der Konzepte von Daten und Metadaten ist der erste Schritt, um sich diesen Themen zu nähern. Die Digitalisierung von Sammlungen in Galerien, Bibliotheken, Archiven und Museen ermöglicht den einfachen Online-Zugang zu einer Fülle historischer und kultureller Materialien. Dadurch können Forschende Quellen von überall auf der Welt studieren und ihr Arbeitsfeld deutlich erweitern.
2. Veränderungen in der Wissensvermittlung und Auswirkungen auf Lehre und Lernen
Digitale Plattformen haben den Zugang zu Forschung demokratisiert, indem sie Open-Access-Publikationen ermöglichen. So können Wissenschaftlerinnen und Wissenschaftler ihre Arbeiten einem globalen Publikum zugänglich machen, ohne die Barrieren der Printveröffentlichung. Digitale Geisteswissenschaftsprojekte verbinden oft Text, Audio, Video und interaktive Elemente und schaffen so dynamischere und ansprechendere Formen wissenschaftlicher Arbeit. Dadurch verändert sich die Art und Weise, wie Forschung präsentiert und rezipiert wird – weg von traditionellen Fachartikeln oder Monografien. Digitale Plattformen fördern zudem interaktivere und kollaborative Lernformen.
3. Erhalt des kulturellen Erbes
Die Digitalisierung unterstützt den Erhalt des kulturellen Erbes, indem sie digitale Kopien von physischen Artefakten, Texten und Kulturerbe-Orten erstellt. So bleibt ihr digitales Abbild erhalten, selbst wenn die Originale im Laufe der Zeit verfallen.
4. Philosophische und ethische Implikationen
Der digitale Wandel in den Geisteswissenschaften wirft wichtige Fragen zur Natur von Wissen, Urheberschaft und Authentizität im digitalen Zeitalter auf. Wissenschaftlerinnen und Wissenschaftler hinterfragen kritisch, wie digitale Werkzeuge unser Verständnis von Kultur, Identität und Geschichte beeinflussen. Digitale Werkzeuge können Wissen demokratisieren, aber je nach Gestaltung und Anwendung auch bestehende Vorurteile verstärken.
5. Interdisziplinäre Zusammenarbeit
Die Digital Humanities sind von Natur aus interdisziplinär: Sie bringen Geisteswissenschaftler*innen mit Informatiker*innen und Datenanalyst*innen zusammen. Diese Zusammenarbeit eröffnet neue Forschungsfragen, Methoden und Erkenntnisformen.
Bereiche, in denen die Digitalisierung eine wichtige Rolle spielt:
- Forschungsmethoden
- Wissensvermittlung
- Kulturerbe
- Zusammenarbeit
- Erhaltung / Bewahrung
Content from Daten
Last updated on 2025-08-25 | Edit this page
Overview
Questions
- Was sind Daten in den Geisteswissenschaften?
- Was sind die Unterschiede zwischen verschiedenen Arten von Daten?
Objectives
Nach Abschluss dieser Lerneinheit sollten die Teilnehmenden in der Lage sein
- zwischen analogen Daten, digitalisierten Daten und genuin digitalen (born-digital) Daten unterscheiden,
- verstehen, wie Daten in der geisteswissenschaftlichen Forschung kategorisiert, erhoben und genutzt werden,
- die Auswirkungen verschiedener Datentypen auf unterschiedliche Forschungsmethoden und Forschungsergebnisse untersuchen.
Datentypen
Analoge Daten: Analoge Daten entstehen in physischen, nicht-digitalen Formaten wie handschriftliche Dokumente, Fotografien oder materielle Objekte.
Digitalisierte Daten: Digitalisierte Daten sind ehemals analoge Informationen, die durch Verfahren wie Scannen, Transkribieren oder Kodieren in digitale Formate überführt wurden. Diese Transformation erweitert nicht nur die Zugänglichkeit, sondern ermöglicht auch die Anwendung digitaler Analysemethoden. Ein differenziertes Verständnis digitalisierter Daten ist zentral, um nachvollziehen zu können, wie analoge Ressourcen für digitale Nutzungskontexte aufbereitet und angepasst werden.
Born-Digital Daten (Genuin digitale Daten): Genuin digitale Daten entstehen direkt in digitalen Umgebungen und existieren ausschließlich in diesen Formaten. Dazu zählen etwa Datenbanken, digitale Texte, audiovisuelle Medien oder computergenerierte Inhalte, die nie in physischer Form vorlagen. Diese Datenform steht exemplarisch für eine digital geprägte Forschungspraxis, in der Daten in Echtzeit erzeugt, verarbeitet und verbreitet werden – und die damit neue Möglichkeiten, aber auch neue Anforderungen für die geisteswissenschaftliche Arbeit schafft.
Übung
Analog vs. Digital – Was sehen wir eigentlich?
Diese Übung lädt dazu ein, die Unterschiede zwischen analogen und digitalen Daten am Beispiel eines Objekts des kulturellen Erbes zu erkunden. Im Mittelpunkt steht die Frage, was geschieht, wenn physische Kunstwerke durch digitale Medien zugänglich gemacht werden. Dazu verwenden wir beispielhaft Daten aus der Sammlung des Metropolitan Museum of Modern Art.
Leitfrage
Mit welcher Art von Daten arbeiten wir, wenn wir mit digitalisierten Kulturobjekten interagieren? Und was passiert mit den Eigenschaften analoger Objekte, wenn sie in digitale Repräsentationen überführt werden?
Schritt 1: Beobachtung
Wähle ein digitales Bild eines Objekts aus der Online-Sammlung des Metropolitan Museum of Modern Art (oder eines anderen digitalen Museumsportals). Reflektiere anschließend über die folgenden Fragen: Was für ein Objekt ist das im Original? Was genau siehst du auf dem Bildschirm – und was bedeutet es, das Objekt als digitale Repräsentation zu sehen? Was geht im Vergleich zur direkten Erfahrung mit dem Original möglicherweise verloren?
Schritt 2: Diskussion
Fragen: Wenn das Original ein analoges (physisches) Kunstwerk ist und wir es auf einem Bildschirm betrachten – mit welcher Art von Daten arbeiten wir dann eigentlich? Was geschieht mit der Materialität des Objekts, wenn es digitalisiert wird? Wie beeinflusst die digitale Repräsentation unser Verständnis oder unsere Interpretation? Was gewinnen wir durch diese Transformation – und was geht dabei verloren?
Schritt 3: Reflektion
Überlege dir: Welche Eigenschaften eines Objekts lassen sich nur schwer oder gar nicht digital erfassen? Welche digitalen Formate (z. B. hochauflösende Bilder, 3D-Modelle, Metadaten) versuchen, diese Einschränkungen auszugleichen? Wo begegnest du in deinem eigenen Fachgebiet der Transformation vom Analogen zum Digitalen? Und wie beeinflusst sie deine Forschung oder Interpretation?
Wir betrachten das Gemälde auf einem Computerbildschirm. Alles, was wir sehen, wird digital angezeigt. Obwohl das ursprüngliche Objekt analog ist, erfolgt unsere Interaktion ausschließlich digital. Das Gemälde wurde digitalisiert – also in Daten umgewandelt (z. B. Pixel, Metadaten), die von Computern gespeichert, verarbeitet, angezeigt, geteilt, durchsucht und bearbeitet werden können. Wir interagieren nicht mit dem analogen Objekt selbst, sondern mit seiner digitalen Repräsentation.
Diese Transformation ermöglicht einen breiteren Zugang, bringt aber auch Einschränkungen mit sich: Aspekte wie Maßstab, Materialität oder tatsächliche Farbwirkung können verloren gehen – wir erleben lediglich eine digitale Annäherung. Das Verständnis dieser Transformation ist zentral für den Umgang mit Daten in den Digital Humanities und entscheidend für die Frage, wie unser Wissen über Kultur durch das digitale Medium geprägt wird.
Mit analogen Daten meinen wir die physischen Artefakte im Museum. Die Sammlung des Museums umfasst zahlreiche materielle Objekte wie Skulpturen, Gemälde und andere Artefakte, die ausschließlich in ihrer ursprünglichen, nicht-digitalen Form existieren. So enthält zum Beispiel die Sammlung altägyptischer Kunst im Metropolitan Museum etwa 30.000 Objekte – wie hier zu sehen ist.
Mit digitalisierten Daten meinen wir zum Beispiel digitalisierte Lichtbilder von Objekten. Hochauflösende Fotografien von Kunstwerken und Artefakten – etwa Gemälden, Skulpturen oder archäologischen Fundstücken – wurden digitalisiert, um sie für Forschung und Öffentlichkeit zugänglich zu machen. Diese Bilder sind über die Online-Datenbank der Museumssammlung abrufbar.
Born-digital Daten sind unter anderem born-digital photographs or videos, sowie digitale Aufzeichnungen und Datenbanken der Museumssammlungen, einschließlich Metadaten und detaillierter Beschreibungen von Kunstwerken. Die Archive des Museums enthalten ebenfalls born-digital Materialien wie Ausstellungsdokumentationen, kuratorische und administrative Unterlagen, die digital erstellt und gescheichrt wurden.
Möglichkeiten und Herausforderungen, die mit den einzelnen Datentypen verbunden sind, sowie deren Wirkungen innerhalb des größeren Forschungssystems.:
Diese Datentypen werden auf unterschiedliche Weise genutzt und prägen sowie unterstützen jeweils spezifische Forschungspraktiken.
Analoge Daten, vorhanden in Magazinen, Archiven oder physischen Sammlungen, bilden die Grundlage für historische und materialbezogene Studien und ermöglichen eine unmittelbare Auseinandersetzung mit den Originalquellen. Ihre haptischen und kontextuellen Eigenschaften sind für das Verständnis von Provenienz und Authentizität von unschätzbarem Wert. Allerdings sind diese Daten häufig nur eingeschränkt zugänglich.
Digitalisierte Daten verändern die Zugänglichkeit einer physischen Quellen grundlegend und ermöglichen den ortsunabhängigen Zugriff über digitale Plattformen und Repositorien. Dieser Wandel demokratisiert die Forschung, indem er geografische Barrieren überwindet und vergleichende Studien erleichtert. Darüber hinaus beinhaltet die Digitalisierung häufig Metadaten und Suchfunktionen, die die Auffindbarkeit und Nutzbarkeit analoger Quellen erheblich verbessern. Die Digitalisierung wirft jedoch Bedenken hinsichtlich der Datenintegrität, eines möglichen Verlusts von Kontext sowie einer bevorzugten Behandlung bestimmter Sammlungen gegenüber anderen auf.
Born-digital data ist, im Gegensatz dazu, vornherein dynamisch angelegt und für die Integration in digitale Umgebungen konzipiert. Sie fördert kollaborative und interdisziplinäre Forschung, da sie in Echtzeit geteilt, aktualisiert und analysiert werden kann. Ihre rechnergestützten Potenziale – etwa für maschinelles Lernen oder Datenvisualisierung – eröffnen neue Wege insbesondere in den Digital Humanities, der Data Science oder der Netzwerkanalyse. Gleichzeitig bringt sie Herausforderungen mit sich: etwa hinsichtlich der Langzeitarchivierung, des Datenschutzes oder der Ephemerität digitaler Formate.
Zudem interagieren diese Datentypen häufig in hybriden Forschungsabläufen. So können beispielsweise digitalisierte analoge Daten durch rechnergestützte Analysen gemeinsam mit born-digital-Daten angereichert werden, wodurch neue Erkenntnisebenen entstehen. Ebenso kann born-digitales Material Anlass geben, analoge Quellen neu zu untersuchen – ein zyklischer Prozess der Entdeckung und Neubewertung. Dieses Zusammenspiel verdeutlicht die sich wandelnde Landschaft der Wissensproduktion, in der verschiedene Datentypen zusammenwirken, um komplexe Forschungsfragen zu adressieren.
Outcome
Wie unterstützen institutionelle Infrastrukturen wie Bibliotheken, Archive und Datenzentren diese Prozesse und wie meistern sie die Herausforderung, Bewahrung, Zugang und Innovation in Einklang zu bringen?
- Analoge Daten werden in Magazinen, Archiven oder physischen Sammlungen aufbewahrt.
- Digitalisierte Daten sind eine Umwandlung analoger Daten in digitale Form.
- Born-digital data haben keine analoge Representation.
Content from Metadaten
Last updated on 2025-07-17 | Edit this page
Overview
Questions
- Was sind Metadaten?
- Was sind die wichtigsten Arten von Metadaten?
Objectives
Nach Abschluss dieser Einheit sollten die Teilnehmenden in der Lage sein
- die Grundlagen von Metadaten zu verstehen,
- Metadaten von eigentlichen Daten zu unterscheiden,
- die wesentlichen Arten von Metadaten zu differenzieren,
- Metadatenkonzepte auf praktische Aufgaben anzuwenden,
- die Bedeutung von Metadaten in den Geisteswissenschaften zu erkennen.
Metadaten: Typen, Funktionen und Kontexte
Metadaten sind Daten, die andere Daten beschreiben. Metadaten liefern aussagekräftige Informationen, die das Auffinden, Identifizieren, Verstehen, Verarbeiten und Aufbewahren der Primärdaten erleichtern.
Daten selbst können strukturiert oder „roh“ sein, d. h. unverarbeitet oder unstrukturiert. Im Gegensatz dazu sind Metadaten immer verarbeitet und strukturiert und so konzipiert, dass sie sowohl für Menschen als auch für Maschinen verständlich sind. Metadaten erfüllen einen funktionalen Zweck, z. B. die Organisation von Materialien in einem Katalog oder die Ermöglichung der Suche und des Abrufs von Ressourcen in einer Datenbank. Sie helfen dabei, wesentliche Eigenschaften von Daten zu vermitteln, wie z. B. deren Herkunft, Zeitraum und geografische Abdeckung.
Es gibt drei Haupttypen von Metadaten:
Deskriptive Metadaten beschreiben eine Ressource für Zwecke wie Auffindbarkeit und Identifizierung. Sie können Elemente wie Titel, Autor, Erstellungsdatum, Medium, Abmessungen und Schlüsselwörter enthalten.
Deskriptive Metadaten sind entscheidend für das Auffinden und Identifizieren von Ressourcen wie Büchern, Zeitschriftenartikeln oder digitalen Archiven in den Geisteswissenschaften, für die Katalogisierung und Analyse von Kunstwerken in Museumsdatenbanken oder wissenschaftlichen Studien und unterstützen Historiker*innen beim Auffinden und Studieren von Primärquellen.
Strukturelle Metadaten geben Auskunft darüber, wie zusammengesetzte Objekte aufgebaut sind bzw. wie ihre einzelnen Bestandteile miteinander verknüpft sind.
Zum Beispiel definiert die strukturelle Metadatenbeschreibung eines digitalisierten mittelalterlichen Manuskripts in einem Online-Archiv die Hierarchie und Organisation des Manuskripts:
- Seitenreihenfolge (z.B., Folio 1 recto, Folio 1 verso)
- Beziehungen zwischen Abschnitten (z. B. Kapitel, Randbemerkungen, Glossen)
- Verknüpfungen zwischen Text und entsprechenden Abbildungen, etwa Buchmalereien oder Annotationen.
Administrative Metadaten liefern Informationen, die für die Verwaltung einer Ressource erforderlich sind – etwa wann und wie sie erstellt wurde, welchen Dateityp sie hat, weitere technische Angaben sowie Informationen darüber, wer Zugriff darauf hat. Es gibt mehrere Unterkategorien administrativer Metadaten, darunter:
− Rechteverwaltungsmetadaten, die sich mit Urheber- und Nutzungsrechten befassen − Metadaten zur Erhaltung, die Informationen zur Archivierung und langfristigen Bewahrung einer Ressource enthalten.
Administrative Metadaten sind entscheidend für das Management des Lebenszyklus von Ressourcen. So informiert etwa die Rechteverwaltung darüber, ob ein/eine Forscher/Forscherin ein Bild rechtlich in einer Publikation verwenden darf, während Erhaltungsmetadaten digitale Archivierungsstrategien unterstützen, um fragile Manuskripte langfristig zu sichern.
Challenge 1:
Gehe noch einmal zu den Online-Ressourcen zurück. Finde die Daten, auf die sich die Metadaten beziehen. Kannst du feststellen, um welche Art von Metadaten es sich handelt?
Die in der Online-Sammlung des Met Museum durchsuchbaren Objekte enthalten in erster Linie beschreibende Metadaten wie Titel, Urheber, Entstehungsdatum und Maße. Administrative Metadaten beschränken sich weitgehend auf die Inventarnummer, wobei zusätzliche – mitunter sensible – administrative (Meta-)Daten möglicherweise nicht veröffentlicht werden. Strukturelle Metadaten sind in der Regel nur in geringem Umfang vorhanden, obwohl sich viele gut dokumentierte Kunst- und Kulturobjekte durchaus für eine detaillierte strukturelle Erfassung eignen würden. Die Erstellung solcher Metadaten erfordert jedoch eine umfassende Bearbeitung, die oft nicht praktikabel ist. Institutionen konzentrieren sich daher meist auf eine grundlegende Erschließung mit minimalen Metadaten; eine vertiefte Katalogisierung erfolgt häufig nur im Rahmen spezifischer Projekte.
Challenge 2:
Ist das Buch „Alice’s Adventures in Wonderland“ („Alice im Wunderland“) Daten oder Metadaten?
Es hängt vom Kontext ab, ob es als Daten (das Buch selbst) oder als Metadaten (der Titel in einem Bibliothekskatalog) betrachtet wird.
Die Unterscheidung zwischen Daten und Metadaten hängt oft vom Kontext ab, in dem die Information verwendet wird. Daten und Metadaten sind relative Begriffe – was in einem Zusammenhang als „Daten“ dient, kann in einem anderen als „Metadaten“ fungieren.
Zum Beispiel wird der Text von „Alice’s Adventures in Wonderland“ – also seine Worte, Kapitel und Erzählstruktur – in der Regel als Daten betrachtet, wenn der Inhalt, die Themen oder sprachliche Merkmale analysiert werden. Der Titel „Alice’s Adventures in Wonderland“ hingegen gilt im Kontext der Katalogisierung als Metadatum. In einem Bibliothekskatalog ist der Titel Teil eines strukturierten Metadatensystems, das dazu dient, das Buch zu beschreiben, zu ordnen und auffindbar zu machen – gemeinsam mit anderen Metadaten wie Autor, Erscheinungsdatum oder ISBN.
Diese Relativität unterstreicht, wie wichtig es ist, die unterschiedlichen Ebenen zu verstehen, auf denen wir mit Informationen interagieren. Im Kern gilt:
- Daten beziehen sich auf den eigentlichen Untersuchungs- oder Nutzungsgegenstand (z. B. den vollständigen Text des Buches).
- Metadaten sind Informationen über diese Daten; sie dienen dazu, sie zu beschreiben, einzuordnen oder ihre Organisation und Auffindbarkeit zu erleichtern (z. B. Titel, Autor oder Genrezuordnung).
Dieses Zusammenspiel von Daten und Metadaten verdeutlicht die vielschichtige Natur des Informationsmanagements und die Notwendigkeit von Präzision im Umgang mit beiden.
- Beschreibende Metadaten beschreiben eine Ressource zu bestimmten Zwecken.
- Strukturelle Metadaten geben an, wie zusammengesetzte Objekte aufgebaut sind.
- Administrative Metadaten liefern Informationen zur Verwaltung einer Ressource.
Content from Speichern und Verarbeiten von Metadaten
Last updated on 2025-08-04 | Edit this page
Overview
Questions
- In welchen Formaten können Daten und Metadaten strukturiert gespeichert werden?
- Was ist eine CSV-Datei und wie ist ihr Inhalt aufgebaut?
Objectives
Nach Beendigung dieser Episode sollten Teilnehmende in der Lage sein
- die Grundstruktur eines CSV-Formats zur Speicherung und Verarbeitung von Metadaten zu beschreiben,
- eine einfache CSV-Datei zu öffnen und zu untersuchen,
- die wichtigsten Unterschiede zwischen einer CSV-Datei und einer
Excel-Datei zu bennen.
Einführung in Dateiformate für Metadatenspeicherung und -verarbeitung
Frage
Kennt ihr Formate, in denen man Daten strukturiert speichern kann?
Eine einfache Möglichkeit stellen die Tabellenblätter in einem Tabellenkalkulationsprogramm dar.
Um Metadaten zu speichern und sie in anderen Kontexten nutzbar zu machen, sind geeignete Formate erforderlich. Die gängigsten Dateiformate für die Speicherung von Metadaten sind XML und JSON. Viele Daten werden auch in dem bekannteren CSV-Format gespeichert, wie ein Beispiel aus der Praxis später zeigen wird.
Interoperabilität
Der Vorteil der Verwendung eines solchen Formats ist die Interoperabilität der Daten. Das bedeutet, dass die Daten von einer Person erfasst und gespeichert werden, aber an anderer Stelle geöffnet, verarbeitet oder mit anderen Daten zusammengeführt werden können.
Aufgabe
Öffne die Dateien “artworksShort.csv” und “artworksShort.xslx” in einem Tabellenkalkulationsprogramm deiner Wahl.
- Was fällt dir auf?
- In welcher Form liegen die Daten vor?
- Welche Vorteile hat diese Art der Erfassung von Daten?
- Warum sind diese Daten interoperabel?
- Beim Öffnen der CSV-Datei werden mehrere Parameter abgefragt.
- Einige Daten in der XSLX-Datei sind mit Farben sowie fett- und kursivgedrucktem Text formatiert. Dies ist in der CSV-Datei nicht zu finden.
- Die Daten liegen in tabellarischer Form vor.
- Die Daten sind in einzelnen Zellen erfasst.
- Die Inhalte sind durch Überschriften in der ersten Zeile
kategorisiert.
- Die Daten liegen in einem digitalen Dateiformat vor, das bearbeitet und weitergegeben werden kann.
Das CSV-Format
Das CSV-Format (comma-separated values) in diesem Beispiel wird normalerweise als Tabelle in einem Tabellenkalkulationsprogramm wie Excel geöffnet, damit es von Menschen strukturiert gelesen werden kann. Wenn man das Format in einem Texteditor öffnet, zeigt sich die Struktur der Datei:
ID;artist;title;date
1;Salvador Dalí;The persistence of memory;1931
2;Walker Evans;Allie Mae Burroughs, Wife of a Cotton Sharecropper, Hale County, Alabama;1936
3;Frida Kahlo;Roots;1943
4;Käthe Kollwitz;Mother with Child over her Shoulder;Before 1917
5;Berthe Morisot;The psyche mirror;1876
1;Georgia O’Keeffe;Sky above clouds IV;1965
3;Banksy;Girl with Ballon;2002Beim Öffnen der CSV-Datei in einem Tabellenkalkulationsprogramm wurden einige Parameter abgefragt, bevor die Inhalte angezeigt werden. Hier ist der Grund dafür:
Die Daten in dieser speziellen CSV-Datei sind durch Semikolons – die so genannten Trennzeichen oder delimiter – getrennt. Die meisten Dateien, die Trennzeichen jeglicher Art nutzen, erhalten oft die Erweiterung .csv, auch wenn das Trennzeichen kein Komma ist, wie das vorliegende Beispiel zeigt. In vielen Dateien ist der Inhalt der Datenfelder in Anführungszeichen eingeschlossen, wenn die Datei in einem Editor geöffnet wird. Dies sieht man in einem Tabellenprogramm nicht. Die einzelenen Datensätze stehen meist in einer Zeile und werden durch einen Zeilenumbruch getrennt. Oft definiert die erste Zeile die Spaltenüberschriften. Werden diese Parameter beim Öffnen der Datei korrekt eingegeben, werden die Daten in die entsprechenden Felder des Tabellenkalkulationspogramms übertragen.
Unterschied zwischen CSV- und XSLX-Dateien
Mit einem XSLX-Format können Daten in mehreren Tabellenblättern in einer einzigen Datei gespeichert und miteinander verknüpft werden. Die Daten sind in Zellen organisiert, die in Zeilen und Spalten angeordnet sind. Sowohl die Zellen als auch die darin enthaltenen Datenwerte können formatiert werden, einschließlich Schriftarten, Farben und Rahmen. Die Daten können mit integrierten Funktionen bearbeitet werden, z. B. für Berechnungen oder Analysen. Es ist auch möglich, die analysierten Daten in Tabellenkalkulationsprogrammen wie Excel zu visualisieren.
Einer der Nachteile ist die begrenzte Anzahl von Zeilen und Spalten - zum Beispiel 1.048.576 Zeilen und 16.385 Spalten pro Arbeitsblatt, abhängig von der Softwareversion. Auch andere Funktionen können von der Softwareversion abhängen. Ältere Tabellen werden in der neuesten Version aufgrund mangelnder Kompatibilität der Funktionen möglicherweise nicht immer korrekt angezeigt.
Das CSV-Format (comma-separated values) speichert tabellarische Daten in einfachem Text, der in Tabellenkalkulationsprogrammen geöffnet werden kann. Es ist daher sowohl von Menschen als auch von Maschinen lesbar. Es wird immer nur eine Tabelle in einer einzigen Datei gespeichert. In diesem Textformat können jedoch mehr Daten in einer Datei gespeichert werden, was es besonders effizient macht. Zudem werden keine überflüssigen Daten wie Formatierungsdaten gespeichert. Daher eignet es sich für die Speicherung und den Austausch von größeren Datenmengen zwischen Anwendungen oder Datenbanken.
Einer der Nachteile ist, dass in diesem Format nur einfache tabellarische Daten gespeichert werden können, nicht aber Daten mit komplexeren Strukturen.
Datenorganisation
Bei der Erfassung von Daten in Tabellen gibt es eine Reihe von Aspekten zu beachten, damit die Daten korrekt verarbeitet werden können. Neben den oben erwähnten kommagetrennten Feldern, die Probleme verursachen können, gibt es noch viele andere Probleme. Datumsangaben oder Namen sind eine große Fehlerquelle. Unterschiedliche Schreibweisen können zu Fehlinterpretationen führen. Wie interpretiert man zum Beispiel das Datum 25-01-11, wenn es in einem einzigen Feld steht? Oder: Welcher Teil des Namens einer Person ist der Vorname und welcher Teil ist der Nachname?
Daher ist ein wichtiger Teil bei der Erfassung von Metadaten die Annotierung, d.h. die korrekte Auszeichnung der Daten. Nimm Walker Evans als Beispiel: Kennzeichnet man ihn als „Künstler“ oder „Fotograf“, können die Benutzer die Rolle im Kontext des Datensatzes verstehen.
Wenn Datumsangaben in einer Tabelle erfassen werden sollen, kann es sich lohnen, Jahr, Monat und Tag in separate Felder aufzuteilen, um das oben beschriebene Problem zu vermeiden.
Weitere Informationen zur Organisation von Daten bietet die Lektion Data Organization in Spreadsheets for Social Scientists
Es gibt bestimmte Datenformate, die einige der hier genannten Probleme lösen, wie etwa die Nutzung einer Auszeichnungssprache (Markup Language). Auszeichnungssprachen werden zur Strukturierung und Formatierung von Text und Daten in maschinenlesbarer Form verwendet. Sie beruhen auf einer Metasprache namens SGML (Standard Generalized Markup Language). SGML ist ein Standard für Auszeichnungssprachen. Sie legt fest, wie die Syntax (Regeln) für Elemente, Attribute und die Dokumentstruktur in einer Auszeichnungssprache zu definieren ist. In der Episode zu XML erfahren Sie mehr dazu.
- Wenn die Tabelle oder Daten formatiert werden müssen oder Daten mit
der Software analysiert werden sollen, eignet sich das XSLX-Format zum
Speichern, Formatieren und Analysieren der Daten.
- Wenn dies nicht der Fall ist oder sehr große Datenmengen vorliegen,
empfiehlt sich ein Format wie CSV, um die Daten zu speichern oder
weiterzugeben.
- Es ist hilfreich, die Daten bei der Erfassung zu annotieren, zum
Beispiel durch Überschriften zu kennzeichnen.
- Sei dir der Probleme bewusst, die entstehen können, wenn zum Beispiel Datums- oder Namensangaben erfasst werden und mache dir vorab Gedanken, welche Form für deine Zwecke geeignet sein könnte.
Content from XML
Last updated on 2025-08-26 | Edit this page
Overview
Questions
- Was ist XML?
- Welche Elemente beinhaltet XML?
- Wie notiert man Daten in XML?
Objectives
Nach Beendigung dieser Episode sollten Teilnehmende in der Lage sein
- das XML-Format für die Speicherung und Verarbeitung von Metadaten beschreiben,
- Syntaxregeln für eine wohlgeformte XML-Datei zu benennen,
- die Struktur einer einfachen XML-Datei zu untersuchen,
- extrahierte Metadaten in ein einfaches XML-Format zu schreiben.
Eines der am häufigsten verwendeten Dateiformate im Kulturbereich ist XML (eXtensible Markup Language). Es wird zur Beschreibung, Strukturierung, Speicherung und Übertragung von Daten verwendet. XML bezieht sich sowohl auf das Dateiformat als auch auf die Syntax, in der die Daten aufgezeichnet werden: die Auszeichnungssprache. Durch die Markierung des Textes mit Tags können Daten und Metadaten in einem einzigen Dokument kombiniert werden.
XML Elemente
Ein XML-Dokument enthält XML-Elemente zur Strukturierung der Daten. Sie werden mit Hilfe von Tags in spitzen Klammern gebildet und sind in ein öffnendes und ein schließendes Tag unterteilt. Das schließende Tag ist durch einen führenden Schrägstrich gekennzeichnet. Dazwischen befindet sich der Inhalt.
Die Tags erhalten einen Namen, der den Inhalt beschreibt:
XML
<photographer>Walker Evans</photographer>
<name>Walker Evans</name>
<artist>Walker Evans</artist>Diese Struktur kommt dir vielleicht bekannt vor. Die Sprache HTML, die für Webseiten verwendet wird, hat eine ähnliche Struktur. Sie basiert ebenfalls auf SGML. HTML ermöglicht es, die typischen Elemente eines textbasierten Dokuments - wie Überschriften, Absätze, Listen oder Tabellen - als solche auf einer Webseite auszuzeichnen und die Seite semantisch zu strukturieren. Im Gegensatz zu HTML, wo es Regeln für die Benennung von Tags gibt - wie z.B. <h1></h1> für Überschriften - können XML-Tags, vorbehaltlich einiger technischer Regeln, frei benannt werden. Dies macht es besonders interessant für die Entwicklung von Metadatenstandards und Ontologien.
Regeln für die Benennung von XML-Tags1
Namen:
- Müssen mit einem Buchstaben oder einem Unterstrich beginnen.
- Dürfen nicht mit den Buchstaben xml (oder XML, oder Xml, etc) beginnen.
- Können Buchstaben, Ziffern, Bindestriche, Unterstriche und Punkte enthalten.
- Dürfen keine Leerzeichen enthalten.
Bewährte Benennungspraktiken und was zu beachten ist:
- Verwende aussagekräftige Namen.
- Verwende kurze und einfach Namen.
- Vermeide - / . / : in den Namen, wie <first-name> (der : ist für Namensräume reserviert, die eine besondere Funktion haben).
- In XML-Tags wird zwischen Groß- und Kleinschreibung unterschieden, sie sind case sensitive. Der Tag <Name> unterscheidet sich von <name>.
- XML schneidet mehrere Leerzeichen nicht ab.
XML bietet auch die Möglichkeit, Kommentare zu verwenden, die nicht automatisch gelesen werden:
In den Kommentaren stehen häufig erklärende Informationen, die das Interpretieren der Tags erleichtern oder Hiweise zur korrekten Erfassung des Inhaltes geben.
In XML müssen alle Elemente ordnungsgemäß verschachtelt sein, was bedeutet, dass ein Element, das innerhalb eines anderen Elements geöffnet wird, auch innerhalb dieses Elements geschlossen werden muss:
Eine Einrückung kann verwendet werden, um die Struktur besser lesbar zu machen, insbesondere wenn die Verschachtelung der Elemente tief ist:
XML
<collection>
<name>MET</name>
<place>collection of the MET in New York</place>
<artist>
<name>Fullname</name>
<dateOfBirth>
<day>Day of Birth</day>
<month>Month of Birth</month>
<year>Year of Birth</year>
</dateOfBirth>
</artist>
</collection>Die hier verschachtelten Daten sehen in einer Zeile geschrieben so aus:
XML
<collection><name>MET</name><place>collection of the MET in New York</place><artist><name>Fullname</name><dateOfBirth><day>Day of Birth</day><month>Month of Birth</month><year>Year of Birth</year></dateOfBirth></artist></collection>Wie dieses Beispiel zeigt, haben XML-Dokumente eine Baumstruktur. Sie beginnen mit dem Wurzelelement und verzweigen sich dann immer tiefer. Das Tag <artist> wird als übergeordnetes Element bezeichnet und die untergeordneten Elemente <name> und <dateOfBirth> sind untergeordnete Elemente. Auf der tieferen Ebene ist <dateOfBirth> das übergeordnete Element für die Tags Tag, Monat und Jahr als untergeordnete Elemente.
Die in der Struktur der XML-Syntax verwendeten Zeichen müssen bestimmte Regeln einhalten. Bestimmte Zeichen, wie z. B. „<“ für „ist kleiner als“, müssen durch eine spezielle Zeichenfolge ersetzt werden, damit sie keine Probleme verursachen. Wenn einfach nur „<“ verwendet wird, versteht XML es als ein öffnendes Tag und erwartet, dass es irgendwann geschlossen wird. Um Fehler in diesem und ähnlichen Fällen zu vermeiden, wird das Zeichen durch eine Entitätsreferenz ersetzt:
| String | Zeichen | Bedeutung | |
|---|---|---|---|
| < | < | kleiner als | |
| > | > | größer als | |
| & | & | und | |
| ' | ’ | Apostroph | |
| " | ” | Anführungszeichen |
Beispiel:
Attribute
In XML wie auch in HTML können Tags auch Attribute haben, die den Inhalt der Tags genauer definieren. Diese Attribute liefern Metadaten für das Element, auf das sie sich beziehen. Sie werden benannt, der Inhalt wird ihnen mit einem = zugewiesen, und sie werden in Anführungszeichen gesetzt:
XML
<title lang="author's original language">Geben Sie den Titel immer in der Sprache des Autors an.</title>
<commonTitle lang="title as commonly known">Geben Sie den Titel immer so an, wie er gemeinhin bekannt ist</commonTitle>Attribute werden häufig in einer Hierarchie verwendet, um Informationen zu erfassen, die für alle zugrunde liegenden Daten gelten:
Der Schrägstrich hier am Ende des Tags (selbstschließender Tag) bedeutet, dass das Element leer und in sich geschlossen ist. Es ist nicht notwendig, ein öffnendes und schließendes Tag zu schreiben, wenn keine anderen Elemente dazwischen liegen oder keine Inhalte vorhanden sind. Man sieht dies oft in der XML-Ausgabe, wenn das Metadatenfeld leer ist.
Am Anfang eines XML-Dokuments steht oft ein so genannter Prolog oder eine Deklaration (declaration):
Dies ist optional, liefert aber Informationen über die verwendete Version und Kodierung2. Wenn er benutzt wird, muss er am Anfang des Dokuments über dem Root-Element platziert werden. Der XML-Prolog oder die Deklaration hat kein schließendes Tag.
XML-Dokumente, die alle diese Regeln erfüllen, werden als „wohlgeformte“ XML-Dokumente bezeichnet.
Übung
Öffne die Datei “moma_artworks.csv”. Wähle den Datensatz eines Werkes aus und schreibe die Daten in XML.
- Erkennst du eine Struktur in den Daten? Können Teile der Daten zum Beispiel unter einer Kategorie gesammelt werden?
- Verwende Einrückungen zur Strukturisierung und Hierarchisierung.
XML
<?xml version="1.0" encoding="UTF-8"?>
<artworks>
<artwork>
<title>Green-Blue-Red (for Parkett no. 35)</title>
<artist>
<name>Gerhard Richter</name>
</artist>
<constituentID>4907</constituentID>
<artistBio>
<bio>German, born 1932</bio>
</artistBio>
<nationality>German</nationality>
<beginDate>1932</beginDate>
<endDate>0</endDate>
<gender>male</gender>
<date>1993</date>
<medium>Multiple of oil on canvas</medium>
<dimensions>composition: 11 7/16 × 15 3/4" (29 × 40 cm); sheet: 11 3/4 × 15 3/4" (29.9 × 40 cm)</dimensions>
<creditLine>Riva Castleman Endowment Fund, Lily Auchincloss Fund, and Gift of Parkett</creditLine>
<accessionNumber>110.1998.1</accessionNumber>
<classification>Multiple</classification>
<department>Drawings & Prints</department>
<dateAcquired>1998-03-05</dateAcquired>
<cataloged>Y</cataloged>
<objectID>61953</objectID>
<url>https://www.moma.org/collection/works/61953</url>
<imageURL></imageURL>
<onView></onView>
<height>29.0</height>
<width>40.0</width>
</artwork>
<artwork>
<title>Untitled</title>
<artist>
<name>Blinky Palermo</name>
</artist>
<constituentID>4474</constituentID>
<artistBio>
<bio>German, 1943–1977</bio>
</artistBio>
<nationality>German</nationality>
<beginDate>1943</beginDate>
<endDate>1977</endDate>
<gender>male</gender>
<date>1970</date>
<medium>Dyed cotton mounted on muslin</medium>
<dimensions>6' 6 3/4\" x 6' 6 3/4\" (200 x 200 cm)</dimensions>
<creditLine>Gift of Jo Carole and Ronald S. Lauder</creditLine>
<accessionNumber>650.1997</accessionNumber>
<classification>Painting</classification>
<department>Painting & Sculpture</department>
<dateAcquired>1997-06-02</dateAcquired>
<cataloged>Y</cataloged>
<objectID>78283</objectID>
<url>https://www.moma.org/collection/works/78283</url>
<imageURL>https://www.moma.org/media/W1siZiIsIjE1MTQ0MCJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=c54d00f27ed284be</imageURL>
<onView></onView>
<height>200.0</height>
<width>200.0</width>
</artwork>
<artwork>
<title>Daylight Savings Time</title>
<artist>
<name>Pierre Roy</name>
</artist>
<constituentID>5065</constituentID>
<artistBio>
<bio>French, 1880–1950</bio>
</artistBio>
<nationality>French</nationality>
<beginDate>1880</beginDate>
<endDate>1950</endDate>
<gender>male</gender>
<date>1929</date>
<medium>Oil on canvas</medium>
<dimensions>21 1/2 x 15" (54.6 x 38.1 cm)</dimensions>
<creditLine>Gift of Mrs. Ray Slater Murphy</creditLine>
<accessionNumber>1.1931</accessionNumber>
<classification>Painting</classification>
<department>Painting & Sculpture</department>
<dateAcquired>1931-01-19</dateAcquired>
<cataloged>Y</cataloged>
<objectID>78294</objectID>
<url>https://www.moma.org/collection/works/78294</url>
<imageURL>https://www.moma.org/media/W1siZiIsIjIzMzkzNyJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=74825d4c62cd5a8a</imageURL>
<onView></onView>
<height>54.6</height>
<width>38.1</width>
</artwork>
<artwork>
<title>The Bather</title>
<artist>
<name>Paul Cézanne</name>
</artist>
<constituentID>1053</constituentID>
<artistBio>
<bio>French, 1839–1906</bio>
</artistBio>
<nationality>French</nationality>
<beginDate>1839</beginDate>
<endDate>1906</endDate>
<gender>male</gender>
<date>c. 1885</date>
<medium>Oil on canvas</medium>
<dimensions>50 x 38 1/8" (127 x 96.8 cm)</dimensions>
<creditLine>Lillie P. Bliss Collection</creditLine>
<accessionNumber>1.1934</accessionNumber>
<classification>Painting</classification>
<department>Painting & Sculpture</department>
<dateAcquired>1934-09-23</dateAcquired>
<cataloged>Y</cataloged>
<objectID>78296</objectID>
<url>https://www.moma.org/collection/works/78296</url>
<imageURL>https://www.moma.org/media/W1siZiIsIjQ0NjA2NyJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=c6bd692fa0fe0685</imageURL>
<onView>"MoMA, Floor 2, 2 South"</onView>
<height>127.0</height>
<width>96.8</width>
</artwork>
<artwork>
<title>Syntheses of Naples</title>
<artist>
<name>Enrico Prampolini</name>
</artist>
<constituentID>4720</constituentID>
<artistBio>
<bio>Italian, 1894–1956</bio>
</artistBio>
<nationality>Italian</nationality>
<beginDate>1894</beginDate>
<endDate>1956</endDate>
<gender>male</gender>
<date>before 1930</date>
<medium>Oil on canvas</medium>
<dimensions>39 3/8 x 39 1/2" (100 x 100.3 cm)</dimensions>
<creditLine>Gift of Dr. Julius Spitzer</creditLine>
<accessionNumber>1.1942</accessionNumber>
<classification>Painting</classification>
<department>Painting & Sculpture</department>
<dateAcquired>1941-12-10</dateAcquired>
<cataloged>Y</cataloged>
<objectID>78299</objectID>
<url>https://www.moma.org/collection/works/78299</url>
<imageURL>https://www.moma.org/media/W1siZiIsIjE4NjgzNSJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=9740d0c731c867c2</imageURL>
<onView></onView>
<height>100.0</height>
<width>100.3</width>
</artwork>
</artworks>Dies ist eine mögliche Lösung. Es gibt weitere Wege, um die Daten zu strukturieren, indem zum Beispiel Elemente wie “artistBio“ oder”gender” innerhalb eines übergeordneten Elements wie “artist“ verschachtelt werden:
Diskussion
Vergleichet eure Ergebnis mit denen anderer Teilnehmenden. Was fällt euch auf?
- XML ist eines der am weitesten verbreiteten Dateiformate für Metadaten.
- Ein XML-Dokument enthält XML-Elemente zur Strukturierung der Daten.
- Attribute liefern zusätzliche Informationen über Elemente oder Gruppen von Elementen.
[1]: w3school XML
elements
[2]: Siehe auch Begriffserläuterung im Glossar.
Content from Einführung in Metadatenstandards, -schemata und -modelle
Last updated on 2025-08-15 | Edit this page
Overview
Questions
- Was ist ein Metadatenstandard?
- Was ist ein Metadatenschema?
- Was ist ein Modell?
Objectives
Nach Beendigung dieser Episode sollten Teilnehmende in der Lage sein,
- die Unterschiede zwischen den Begriffen Metadatenstandard, Metadatenschema und Metadatenmodell anhand von zentralen Aspekten wiederzugeben.
Standard, Schema oder Modell?
Die Begriffe Metadatenstandard, Metadatenschema und Metadatenmodell werden oft synonym verwendet. Im Folgenden wird versucht, zwischen den Begriffen zu differenzieren. Es muss jedoch betont werden, dass dies kein universeller Anspruch ist; vielmehr soll es ein besseres Verständnis der Strukturen der Datenstandardisierung ermöglichen, da es keine allgemein akzeptierten Definitionen dieser Begriffe gibt.
Metadaten-Standard
Ein Metadatenstandard ist eine technische Spezifikation, die beschreibt, wie Daten erfasst oder strukturiert werden sollten. Es gibt verschiedene Möglichkeiten, Daten zu standardisieren. Zwei der wichtigsten Konzepte werden in dieser Lektion vorgestellt. Zum einen wird jedes Element oder Datenfeld eindeutig benannt (z. B. Autor, Titel usw.) und kann durch Regeln in Form von Attributen (z. B. Datentyp) spezifiziert werden. Andererseits kann eine Struktur für die Erfassung der Daten in Form von Gruppen oder Kategorien definiert werden, z. B. administrative, technische und beschreibende Metadaten. Beide Methoden liefern eine grundlegende Beschreibung und Organisation der Daten und standardisieren sie dadurch. Natürlich ist auch eine Kombination der beiden Methoden möglich.
Für verschiedene Themen und Fachgebiete gibt es unterschiedliche Standards. Damit wird sichergestellt, dass z.B. die Regeln für die Erfassung von Daten in einem Archiv oder einer Bibliothek berücksichtigt werden. Das Provenienzprinzip in Archiven oder das Pertinenzprinzip in Bibliotheken lassen sich auf diese Weise abbilden.
Beispiel
Struktur der Metadaten:
- Administrative Metadaten
- Beschreibende Metadaten
- Strukturelle Metadaten
- Technische Metadaten
Metadaten-Elemente:
- Ersteller
- Herausgeber
- Datum
- Rechte
- Paginierung
- Dateiformat
- Titel
Metadatenelemente innerhalb einer Struktur:
- Administrative Metadaten
- Herausgeber
- Rechte
- Beschreibende Metadaten
- Ersteller
- Datum
- Titel
- Strukturelle Metadaten
- Paginierung
- Technische Metadaten
- Dateiformat
Metadaten-Schema
Ein Metadatenschema wird meist zur Strukturierung von Daten in einem bestimmten Kontext verwendet, und es gibt unzählige Standards für jede Disziplin oder einen spezifischen Zweck. Während der Entwicklungsphase der Datenstruktur kann zudem ein vorhandener Metadatenstandard integriert werden. So wird der, in der folgenden Episode behandelte, Dublin Core Standard oft als Grundlage genutzt, um dessen Felder in ein spezifisches Modell zu übernehmen.
Stelle dir vor, du möchtest das Foto eines Gebäudes beschreiben. In den Metadaten gibt es ein Element namens „creator“. Welchen Namen würdest du hier erfassen? Den des Fotografen oder den des Architekten? Möglich wäre es die „Rolle“ als Metadatenelement hinzufügen, um den Kontext der personenbezogenen Daten weiter zu beschreiben. Möglicherweise sollen die Daten für das Foto und das abgebildete Gebäude getrennt erfasst werden, um die Informationen korrekt anzuzeigen. Ein Schema kann eine benutzerdefinierte Struktur oder die Hierarchie einer Sammlung abbilden sowie Datenfelder für bestimmte Themen definieren. Ein Schema stellt die Daten also in einen gewünschten Kontext und legt die Beziehungen zwischen den enthaltenen Informationen fest.
Konzeptionelles Modell
Konzeptionelle Modelle, auch semantische Datenmodelle
genannt, sind in der Regel Abstraktionen von realen Entitäten. Sie
werden verwendet, um die Daten einer Sammlung oder eines spezialisierten
Bereichs auf abstrakte Weise formal zu erfassen. Ein Beispiel für ein
solches Modell ist das Entity-Relationship-Modell, das die Beziehung
zwischen zwei Datenentitäten beschreibt. Zum Beispiel kann die Beziehung
zwischen der Entität des Autors „Franz Kafka“ und der Entität des Buches
„Der Prozess“ durch die Beziehung „hat geschrieben“ definiert
werden.
Der Vorteil dieser Beziehung ist, dass sie eine flexible Verknüpfung von
Daten ermöglicht. Darüber hinaus kann die Entität „Buch“ mit der Entität
“Verlag” über die Beziehung „hat veröffentlicht“ verknüpft werden.
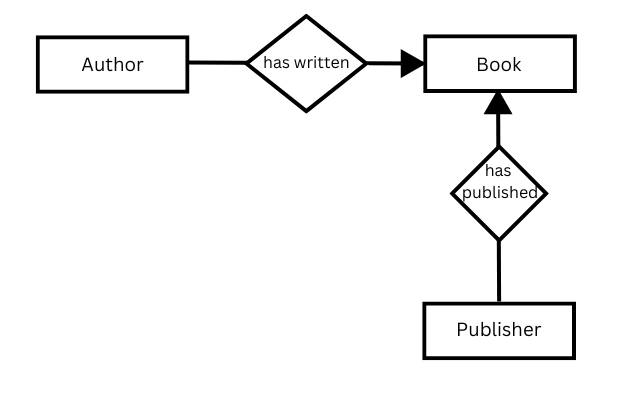
Im konzeptionellen Modell werden die Daten in Form von Tripeln modelliert. Ein Tripel besteht aus einem Subjekt, einem Objekt und einem Prädikat. Das Prädikat beschreibt die Beziehung zwischen dem Subjekt, der zu beschreibenden Entität, und dem Objekt (der mit dem Subjekt verbundenen Entität):
Autor (Subjekt) hat geschrieben (Prädikat) Buch (Objekt).
Ein Objekt kann das Subjekt eines anderen Tripels werden und umgekehrt, wie das obige Beispiel zeigt.
Dieser Ansatz wird hauptsächlich im Semantic Web verwendet, wo er als Grundgerüst für verknüpfte offene Daten (Linked Open Data) dient. Linked Open Data (LOD) zielen darauf ab, ein Höchstmaß an Verknüpfung zwischen Datensätzen zu erreichen. Entitäten werden in diesem Zusammenhang mit eindeutigen Bezeichnern in den Metadaten versehen, die wiederum Entitäten darstellen, die über eigene Metadaten verfügen. Zur Veranschaulichung: Eine Entität kann durch ihren Bezeichner im Kontext der Wissensdatenbank der Wikimedia Foundation, bekannt als “Wikidata”, beschrieben werden. Durch die Herstellung dieser Verknüpfungen werden die in diesem Zusammenhang verfügbaren Daten indirekt genutzt. Wie dies praktisch aussieht, erfahren Sie in der Episode zu RDF.
Übung
Diskutiert das folgende Diagramm in kleinen Gruppen. Was wird gezeigt? Wie werden Daten miteinander verknüpft? Fallen euch weitere Daten ein, die man verlinken könnte?
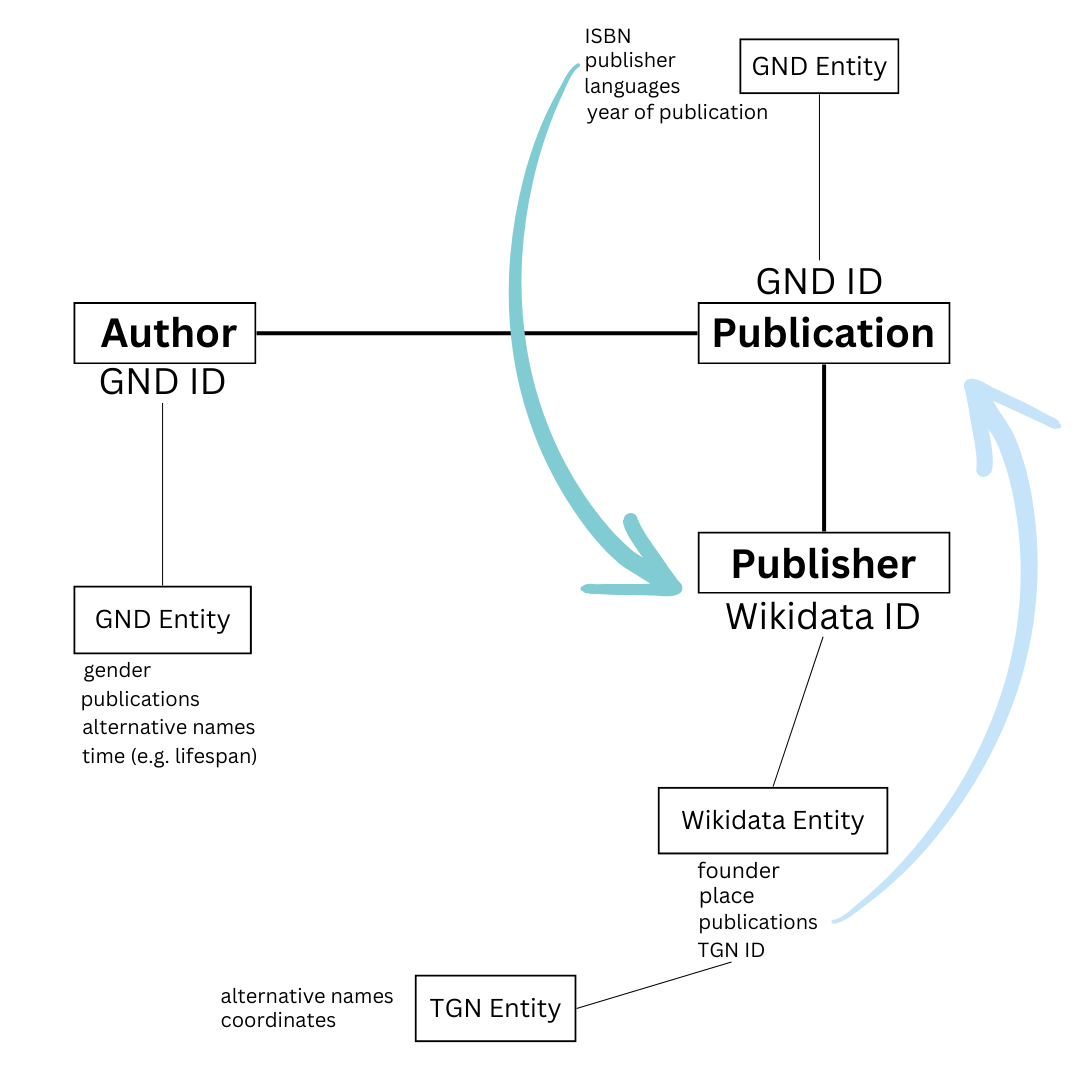
Nicht nur der Name des Autors ist als Entität enthalten, sondern auch sein GND-Datenbank-Identifikator. Die Gemeinsame Normdatei (GND), die von der Deutschen Nationalbibliothek verwaltet wird, ist eine umfassende Datenbank, die Personen, Körperschaften, Konferenzen, Geografien, Sachgebiete und Werke beschreibt. Innerhalb der GND ist die Entität Autor auch eine Metadaten-Entität, die biografische Daten enthält. Durch die Verknüpfung dieser beiden Entitäten werden ihre Daten in einem einzigen Datensatz zusammengefasst, so dass keine separaten Datensätze mehr erforderlich sind. Die Veröffentlichung hat ebenfalls einen Datensatz in der GND-Datenbank, und diese Entität ist mit allen Metadaten verknüpft, die mit der Veröffentlichung verbunden sind, wie z.B. das Erscheinungsjahr. In diesem Beispiel hat der Verlag eine eigene Entität in Form eines Wikidata-Datensatzes, mit dem er verknüpft ist. Die Metadaten in dieser Entität enthalten Informationen über den Standort des Verlags, die mit einem Identifikator verknüpft sind. In diesem Beispiel ist dies die TGN-ID. Der Getty Thesaurus of Geographic Names (TGN) dient als Standarddatenbank für geografische Namen, in der verschiedene Schreibweisen, einschließlich historischer Schreibweisen, sowie Koordinaten und Länderzugehörigkeit neben anderen Attributen erfasst werden. Auf diese Weise entsteht ein Datennetz, das je nach Verfügbarkeit der Daten nach Bedarf erweitert werden kann. Es gibt viele andere Normdaten, kontrollierte Vokabulare und Thesauri, die Informationen über Entitäten wie Objekte, Vokabeln, Begriffe usw. liefern. Sie alle können verwendet werden, um das Netzwerk zu einem Graphen zu erweitern.
Standards für Datenwerte
Standards für Datenwerte gibt es in verschiedenen Formen. Sie ermöglichen, dass Datenwerte, also Inhalte, standardisiert erfasst und damit eindeutig identifizierbar werden. Dazu gehören neben den bekannten ISO-Werten für die Erfassung von Datumsangaben unter anderem auch kontrollierte Vokabulare, Thesauri (hierarchische Listen verwandter Begriffe) und Normdaten (Listen standardisierter Namen oder Begriffe für Entitäten wie Autoren, Künstler oder Organisationen). Sie gewährleisten die Konsistenz der zur Beschreibung von Ressourcen verwendeten Begriffe (z. B. Getty Art & Architecture Thesaurus, Virtual International Authority File - VIAF) wie Fachvokabular oder Namen von Personen, Institutionen und Orten. Wertestandards sind unerlässlich, um die Auffindbarkeit zu verbessern und sicherzustellen, dass Metadatensätze über verschiedene Datensätze und Systeme hinweg konsistent und genau sind.
Die Begriffe Metadatenstandard, Metadatenschema und Metadatenmodell werden häufig synonym verwendet. Sie lassen sich grob wie folgt unterscheiden: - Ein Metadatenstandard beschreibt die Elemente oder die Struktur von Metadaten und ist hauptsächlich für die technische Umsetzung definiert. - Ein Metadatenschema bietet eine Struktur für Metadaten innerhalb eines bestimmten Inhalts, wobei häufig bestehende Metadatenstandards integriert werden. - Ein Metadatenmodell ist ein abstraktes und theoretisches Modell, das Metadaten in ihrem Kontext beschreibt.
Content from Metadata Encoding & Transmission Standard (METS)
Last updated on 2025-08-15 | Edit this page
Overview
Questions
- Was ist der Metadata Encoding & Transmission Standard?
- Welches sind die wichtigsten Elemente des Standards?
Objectives
Nach Beendigung dieser Episode sollten Teilnehmende in der Lage sein
- die wesentlichen Konzepte des Metadata Encoding & Transmission
Standards zu beschreiben,
- die wichtigsten Elemente zur Strukturierung von Daten in METS zu benennen.
METS Metadata Encoding & Transmission Standard
METS ist ein von der Library of Congress bereitgestelltes XML-Format, um digitale Sammlungen von Objekten mit Metadaten zu beschreiben. Der Standard legt keinen Namen oder eine Reihenfolge für die Metadatenfelder selbst fest, sondern dient dazu, diese in einer standardisierten Weise zu strukturieren. Er wird häufig für die Langzeitarchivierung verwendet und unterstützt das digitale Sammlungsmanagement. Es lassen sich Informationen über die Herkunft digitaler Objekte ebenso abbilden, wie Verwaltungs- oder Strukturinformationen zur Sammlung.
Die Metadaten werden in eine von sieben Sektionen eingeordnet:
- METS Header: Metadaten, die das METS-Dokument selbst beschreiben, einschließlich Informationen wie Ersteller oder Herausgeber des METS-Dokuments usw.
- Descriptive Metadata Section: Der Abschnitt enthält die Erschließungsdaten des Objekts. Hier kann auf beschreibende Metadaten außerhalb des METS-Dokuments verwiesen werden oder er kann intern eingebettete beschreibende Metadaten enthalten, oder beides.
- Administrative Metadata Section: Dieser Abschnitt enthält Informationen darüber, wie Dateien erstellt und gespeichert wurden, Urheberrechte oder auch Metadaten über das ursprüngliche Quellobjekt, von dem das digitalisierte Objekt stammt.
- File Section: Die Datei-Sektion listet alle Dateien auf, die zum digitalen Objekt gehören, wie etwa verschiedene Versionen von Digitalisaten.
- Structural Map: Sie skizziert eine hierarchische Struktur des digitalen Objekts.
- Structural Links: Hier werden alle Hyperlinks gelistet, wie sie etwa für die Archivierung von Webseiten unbedingt notwendig sind.
- Behavioral Section: Diese Sektion kann verwendet werden, um ausführbare Verhaltensweisen oder Funktionalitäten mit dem Inhalt des METS-Objekts zu verknüpfen.
Die grundlegende XML-Syntax einer METS-Datei sieht folgendermaßen aus:
XML
<mets>
<metsHdr/><!-- METS Header -->
<dmdSec/><!-- Descriptive Metadata Section -->
<amdSec/><!-- Administrative Metadata Section -->
<fileSec/><!-- File Section -->
<structMap/><!-- Structural Map -->
<structLink/><!-- Structural Links -->
<behaviorSec/><!-- Behavioral Section -->
</mets>Beispiele und Erklärungen zu den einzelnen Sektionen finden sich im Tutorial zum Standard.
Übung 1
Verwende das Beispiel aus der XML-Übung und ordne die Metadatenelemente der Struktur des METS-Standards zu.
Eine Lösung zum ersten Datensatz aus den Beispieldaten der XML-Übung kann so aussehen:
XML
<mets>
<metsHdr>
<creator>Moma</creator>
<editor>me</editor>
<creationdate>today</creationdate>
</metsHdr>
<dmdSec>
<artwork>
<title>Green-Blue-Red (for Parkett no. 35)</title>
<date>1993</date>
<medium>Multiple of oil on canvas</medium>
<dimensions>composition: 11 7/16 × 15 3/4" (29 × 40 cm); sheet: 11 3/4 × 15 3/4" (29.9 × 40 cm)</dimensions>
<department>Drawings & Prints</department>
<artist>
<name>Gerhard Richter</name>
<constituentID>4907</constituentID>
<artistBio>
<bio>German, born 1932</bio>
</artistBio>
<nationality>German</nationality>
<beginDate>1932</beginDate>
<endDate>0</endDate>
<gender>male</gender>
</artist>
</dmdSec>
<amdSec>
<creditLine>Lillie P. Bliss Collection</creditLine>
<accessionNumber>1.1934</accessionNumber>
<dateAcquired>1998-03-05</dateAcquired>
<cataloged>Y</cataloged>
<objectID>61953</objectID>
</amdSec>
<fileSec>
<url>https://www.moma.org/collection/works/78296</url>
<imageURL>https://www.moma.org/media/W1siZiIsIjQ0NjA2NyJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=c6bd692fa0fe0685</imageURL>
<onView>"MoMA, Floor 2, 2 South"</onView>
</fileSec>
<structMap/>
<structLink/>
<behaviorSec/>
<onView></onView>
</mets>Übung 2
Die Webseite der Library of Congress listet verschiedene Beispiele für die Umsetzung des Standards. Schaue dir einige davon an. Was fällt auf?
- In vielen Beispielen wird der MODS-Standard innerhalb der METS-Struktur verwendet. Vielfach wird daher auch vom Austauschformat METS/MODS gesprochen.
- Die letzten Abschnitte fehlen oft oder enthalten nicht viele Daten.
- Die amdSec enthält technische Informationen zu den technischen Mitteln der Digitalisierung, wie Kamera oder Scanner und deren Einstellungen.
- Die amdSec ist manchmal in weitere Abschnitte unterteilt, z. B. Rechte und technische Daten. Es wird also eine weitere Strukturierung innerhalb der Sektionen vorgenommen.
- METS dient als Container zur Strukturierung von Metadaten.
- Die Metadatenfelder selber werden meist in einem spezifischen Standard erfasst und dann in die METS-Struktur integriert. Dazu gehören Standards wie Cublin Core, MODS oder MARC.
Content from Dublin Core Metadaten Standard
Last updated on 2025-08-04 | Edit this page
Overview
Questions
- Was ist das Dublin Core Metadata Element Set (DC)?
- Was ist der Unterschied zwischen einfachem und qualifiziertem Dublin Core?
Objectives
Nach Beendigung dieser Episode sollten Teilnehmende in der Lage sein
- die wichtigsten Elemente des Dublin Core Metadata Element Set zu
identifizieren,
- zwischen einfachem und qualifiziertem Dublin Core zu unterscheiden,
- einfach Metadaten im Dublin Core Standard zu erfassen.
Dublin Core Metadata Element Set
Der Dublin Core ist ein einfacher Metadatenstandard. Er wurde 1998 erstmals von der Dublin Core Metadata Initiative veröffentlicht. Die einfache Version des Standards besteht aus den folgenden 15 Kernelementen zur Beschreibung einer Ressource:
- Contributor
- Coverage
- Creator
- Date
- Description
- Format
- Identifier
- Language
- Publisher
- Relation
- Rights
- Subject
- Title
- Type
Im Gegensatz zu anderen Metadatenstandards oder Schemata können die Felder der Kernelemente in beliebiger Reihenfolge und mehrfach erscheinen. Zudem sind sie alle optional. Dublin Core definiert die Metadatenfelder selbst, jedoch nicht deren Struktur, weshalb es oft mit Strukturierungsstandards wie METS kombiniert wird.
Übung
Dir liegt ein Foto von Johan Hagemeyer vor. Es trägt den Titel „Albert Einstein, Pasadena“. Darauf ist Albert Einstein zu sehen. Es wurde im Jahr 1931 aufgenommen und im Jahr 1962 an das Museum ausgeliehen. Das Foto stammt aus dem Nachlass des Fotografen. Albert Einstein lebte von 1879 bis 1955 und war zum Zeitpunkt der Aufnahme 52 Jahre alt. Der Fotograf Johan Hagemeyer lebte von 1884 bis 1962 und das Foto wurde in Pasadena aufgenommen. Der Aufnahmeort ist New York. Das Foto misst 24,6 × 18,7 cm. Das Passepartout hat die Maße 45,6 × 35,4 cm.
Das Objekt befindet sich in der MET collection. Schau Dir die Spezifikationen auf der Webseite an, wenn du dir unsicher bist, wie du die Daten erfassen kannst.
Welche Information können in den Felder der 15 Kernelemente wie erfasst werden? Warum wählst du bestimmte Felder aus oder warum andere nicht?
Diskutiert in kleinen Gruppen.
- contributor: MET (als verwahrende und verwaltende Institution)
- coverage: New York (als Ort der verwahrenden und verwaltenden Institution)
- creator: Johan Hagemeyer (als Fotograf)
- date: 1931 (als Einreichungsdatum beim MET)
- description: portrait of Albert Einstein
- format: 24.6 × 18.7 cm (Foto) oder 45.6 × 35.4 cm (Gesamtgröße)
- identifier: ?
- language: en (RFC 4646 standard)
- publisher: MET
- relation: andere Fotografien von Johan Hagemeyer oder andere Bilder mit ähnlichem Inhalt
- rights: © 2013 Jeanne Hagemeyer – All Rights Reserved
- source: ?
- subject: portrait, Albert Einstein
- title: Albert Einstein, Pasadena
- type: Gelatinesilberdruck
Dies ist eine von mehreren möglichen Lösungen.
Diskussion
Was habt ihr diskutiert? Was waren die Herausforderungen bei der Zuordnung?
Habt ihr darüber diskutiert, welches Datum in das date-Feld gehört? Woher wissen wir nun, welches Datum genau gemeint ist? Das Datum der Erstellung des Objekts, das der Digitalisierung, der Veröffentlichung oder das der Übermittlung an die Institution?
Die ursprünglichen Kernelemente von Dublin Core wurden erweitert, um solche und andere Informationen über die Daten zu präzisieren.
Qualified Dublin Core
Zunächst wurden Qualifier eingeführt. Ein Qualifier erweitert ein einfaches Element.
Ein einfaches Dublin-Core-Element sieht folgendermaßen aus:
dc.relation
dc beschreibt den so genannten Namespace. Ein Namespace identifiert einen Standard, wie in diesem Fall dc für Dublin Core und wird euch im Bereich der Metadaten und XML immer wieder begegnen. relation beschreibt das Element. Aber um was für eine Beziehung handelt es sich genau? Nun wird der Qualifier ergänzt, der das Element spezifiziert, z.B.:
dc.relation.hasversion oder dc.relation.isversionof
Mit diesen Erweiterungen wird das Feld relation für die Versionierung eines Objekts oder eine Datei verwendet. Es kann also sowohl eine, z.B. digitale, Version haben als auch eine Version eines anderen, z.B. analogen, Objekts sein oder eine ältere bzw. neuere Version des erfassten Objekts, wie es etwa bei Software vorkommen kann.
Übung
Schaue dir das date-Element genauer an. Eine Liste aller authorisierten Qualifier befindet sich auf der Dublin Core Webseite. Welcher Qualifier ist für welche Datumsangabe der Fotografie Hagemeyers geeignet?
- dc.date.created: 1931
- dc.date.submitted: 1962
- dc.date.copyrighted: 2013
- dc.date.issued: Datum, an dem das Bild digital in der Websammlung veröffentlicht wurde
DCMI Metadata Terms
2022 publizierte die Dublin Core Metadata Initiative ein erweitertes Set von Elementen:
Included are the fifteen terms of the Dublin Core™ Metadata Element Set (also known as “the Dublin Core”) plus several dozen properties, classes, datatypes, and vocabulary encoding schemes. The “Dublin Core” plus these extension vocabularies are collectively referred to as “DCMI metadata terms” (“Dublin Core terms” for short). These terms are intended to be used in combination with metadata terms from other, compatible vocabularies in the context of application profiles.1
In diesem Set werden alle vorhandenen Kernelemente zusammengefasst und durch ergänzende Felder erweitert und präzisiert, zum Beispiel durch dateAccepted oder zusätzliche Felder wie abstract.
Die Terms:
| abstract | accessRights | accrualMethod | accrualPeriodicity | accrualPolicy |
| alternative | audience | available | bibliographicCitation | conformsTo |
| contributor | coverage | created | creator | date |
| dateAccepted | dateCopyrighted | dateSubmitted | description | educationLevel |
| extent | format | hasFormat | hasPart | hasVersion |
| identifier | instructionalMethod | isFormatOf | isPartOf | isReferencedBy |
| isReplacedBy | isRequiredBy | issued | isVersionOf | language |
| license | mediator | medium | modified | provenance |
| publisher | references | relation | replaces | requires |
| rights | rightsHolder | source | spatial | subject |
| tableOfContents | temporal | title | type | valid |
Diskussion
Wie ist eure Meinung zu dem erweiterten Metatdatenset? Fehlen aus euren Fachgebieten zum Beispiel noch spezielle Felder? Könnt ihr euch vorstellen für ein in eurem Fachgebiet relevantes Objekt alle Felder auszufüllen?
Sehr wahrscheinlich werdet ihr feststellen, dass mit den im Dublin-Core-Standard vorgegebenen Metadatenfeldern nicht alle Objekte erfasst werden können. Auch können nicht alle Felder immer ausgefüllt werden. Daher gibt es viele weitere Standards oder Schemata, die für das jeweilige Fachgebiet oder spezielle Objekte des kulturellen Erbes erstellt worden sind.
- Der Dublin-Core-Standard umfasst einen einfachen Satz von 15
Elementen sowie einen erweiterten Satz mit zusätzlichen Eigenschaften,
Klassen, Datentypen und Kodierungsschemata.
- Alle Felder sind optional, nicht obligatorisch, können mehrfach und in beliebiger Reihenfolge erscheinen. Dublin Core definiert die Metadatenfelder selbst, aber nicht die Struktur für sie.
[1]: DCMI Metadata Terms
1↩︎
Content from Resource Description Framework (RDF)
Last updated on 2025-08-15 | Edit this page
Overview
Questions
- Was ist Resource Description Framework (RDF)?
- Wie können Informationen durch Triples und URI miteinander verlinkt
werden?
Objectives
Nach Beendigung dieser Episode sollten Teilnehmende in der Lage sein
- das Konzept des Resource Description Framework (RDF) zu beschreiben,
- die Elemente eines Triples zu benennen,
- URI für RDF-Triple zu finden und RDF-Statements zu kreieren.
RDF wurde ursprünglich vom World Wide Web Consortium (W3C) als Standard für die Beschreibung von Metadaten konzipiert. Es gilt heute als ein grundlegender Baustein des Semantic Web und ähnelt den klassischen Methoden zur Modellierung von Konzepten, wie dem in der Einleitung erwähnten Entity-Relationship-Modell.
Daten in RDF sind Aussagen über Ressourcen. Diese Aussagen werden als Tripel modelliert. Die Menge der Tripel bildet einen (mathematischen) Graphen und wird RDF-Modell genannt.
XML
<subject/><predicate/><object/>
<artist>Frida Kahlo></artist><creator>is creator of</creator><artwork>The two fridas</artwork>Das Subjekt und das Prädikat sind immer Ressourcen. Das bedeutet, dass es sich um Entitäten mit einem erweiterten Satz an Informationen handelt. Das Objekt kann entweder eine Ressource oder ein Literal sein. Literale sind Zeichenketten, die anhand eines bestimmten Datentyps wie boolesche Werte, Zahlen oder Daten interpretiert werden können. Eindeutige Bezeichner (z.B. URI) werden zur Identifizierung von Ressourcen verwendet.
Ein Uniform Resource Identifier (URI) ist ein Bezeichner, der aus einer Zeichenfolge besteht, die zur Identifizierung einer abstrakten oder physischen Ressource verwendet wird. Sie sind ähnlich aufgebaut wie eine Webadresse (URL). Die bereits erwähnten GND- oder Wikidata-IDs sind Beispiele dafür. Mit Hilfe der URI können verschiedene Quellen miteinander verknüpft werden. Erinnern Sie sich an die Grafik in der Einleitung.
Das Prädikat wird ebenfalls durch einen URI definiert. Dies ist z.B. möglich, wenn die Beziehung durch einen Metadatenstandard definiert ist. Die Metadatenfelder der Standards haben ihren eigenen URI. Die Beziehung zwischen einer Künstlerin und ihrem Kunstwerk kann unter mit dem Dublin Core-Element “creator” modelliert werden.
<https://www.wikidata.org/wiki/Q5588><http://purl.org/dc/terms/creator><https://www.wikidata.org/wiki/Q3232010>Dieses Beispiel drückt dasselbe aus, wie das vorherige Beispiel: Frida Kahlo ist die Schöpferin von “Die zwei Fridas”. Dazu werden die Identifikatoren von Wikidata und Dublin Core verwendet.
Technisch gesehen kann RDF in mehreren Formaten implementiert werden, darunter JSON-LD und RDF/XML - zwei spezielle Formate von JSON und XML für RDF.
Übung
Schaue dir den Wikidata-Eintrag von Frida Kahlos Gemälde “Die zwei Fridas” genauer an. Gibt es einen alternativen Weg das Prädikat zu beschreiben anstelle der Nutzung von Dublin Core?
creator
property:
Die in Wikidata für eine Entität aufgeführten Informationen sind alle
mit Eigenschaften wie Ort, Genre, Ersteller usw. versehen. Diese
Eigenschaften haben selbst einen Bezeichner und sind daher
standardisiert. Alle Bilder können auf einheitliche Weise modelliert
werden. Die Eigenschaft „creator“ kann ähnlich wie das Dublin
Core-Element „creator“ verwendet werden.
Exercise
Nutze Wikidata, um die folgenden Aussagen zu modellieren:
1) Michelangelo hat die Pietà geschaffen.
2) Michelangelo wurde in Caprese Michelangelo geboren.
3) Die Pietá befindet sich im Petersdom.
<https://www.wikidata.org/wiki/Q5592><https://www.wikidata.org/wiki/Property:P170><https://www.wikidata.org/wiki/Q235242>
<https://www.wikidata.org/wiki/Q5592><https://www.wikidata.org/wiki/Property:P19><https://www.wikidata.org/wiki/Q52069>
<https://www.wikidata.org/wiki/Q235242><https://www.wikidata.org/wiki/Property:P276h><ttps://www.wikidata.org/wiki/Q12512>- RDF ist ein Standardmodell für den Datenaustausch im Web.
- Aussagen werden als Tripel modelliert. Mithilfe von URI verknüpfen diese Tripel Daten (und damit alle dahinter stehenden Informationen) und bilden einen (mathematischen) Graphen.