All in One View
Content from Getting Started
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- What does digitalisation mean for the humanities?
- How is digitalisation changing the humanities?
Objectives
After completing this episode, participants should be able to
- providing a basic explanation of the theoretical and methodological implications of working with data.
Introduction
digitalisation profoundly impacts the humanities by transforming how knowledge is produced, accessed, and interpreted. Almost everything today is reduced to data, interconnected through processes of digitization, visualization, and publication. Culture and history are increasingly manifested in networked forms, a development greatly enhanced by digital technologies. In this context, data and metadata play essential roles. This lesson is developed as an introduction to the meaning of data and metadata in the Humanities. Learners will get familiar with concepts of data and metadata as well as formats such as XML and JSON and metadata standards.
Exploratory Questions
Take a moment to reflect:
- Where do you get your information?
- How do you write your texts?
- How do you connect with institutions, both academically and professionally?
- Do you rely on paper copies of archival documents, or do you use digital photos of them?
- Have you ever visited an archive to conduct research in person?
- Have you ever explored a museum’s (or library’s) website to access digital resources?
Think about how many aspects of your work and daily life are now digital and how much of this vast digitalisation feels like second nature.
Challenge
Reflect on the last topic you worked on. Look for online resources that could support your research or deepen your understanding. What challenges did you encounter when researching or interpreting information published online?
digitalisation profoundly impacts the humanities by transforming how knowledge is produced, accessed, and interpreted. Almost everything today is reduced to data, interconnected through processes of digitization, visualization, and publication. Culture and history are increasingly manifested in networked forms, a development greatly enhanced by digital technologies.
In this context, data and metadata play an essential roles. Data refers to raw information such as texts, images, or records, while metadata provides context — descriptions, tags, or details about how and when the data was created.
The foundation of digitalisation is the creation of data. Whether it’s text, image, or sound, everything is converted into data that must be described and organized. This is where metadata, i.e. information about the data, becomes crucial.
When working with digital resources, both data and metadata are critical for organizing, searching, and interpreting information. Your challenges with doing research online reflect the complexities of managing these elements. These complexities include ensuring accuracy, maintaining context, and effectively handling large amounts of information. Before moving to the more hands-on parts of the lesson, let’s briefly discuss the areas in which digitization is important for the humanities.
1. Transformation of Research Methods
Digital tools allow researchers to work with large amounts of data, such as scanned texts, images, or historical documents. Techniques like text mining, pattern recognition, and data visualization help uncover new insights that traditional methods can’t easily achieve. Don’t worry if you’re not familiar with these methods. Understanding the concepts of data and metadata is the first step into these topics. The digitization of collections in galleries, libraries, archives, and museums provides easy online access to a wealth of historical and cultural materials. This enables researchers to study sources from anywhere in the world, significantly broadening the scope of their work.
2. Changes in Dissemination of Knowledge and Impact on Teaching and Learning
Digital platforms have democratized access to research by enabling open-access publishing, allowing scholars to share their work with a global audience without the barriers of print publication. Digital humanities projects often combine text, audio, video, and interactive elements, creating more dynamic and engaging forms of scholarship. This shifts how research is presented and consumed, moving beyond customary academic articles or monographs. Digital platforms facilitate more interactive and collaborative forms of learning.
3. Preservation of Cultural Heritage
Digitization helps preserve cultural heritage by creating digital copies of physical artefacts, texts, and sites, preserving their digital model despite their physical decay.
4. Philosophical and Ethical Implications
The digital turn in the humanities raises important questions about the nature of knowledge, authorship, and authenticity in the digital age. Scholars critically examine how digital tools shape our understanding of culture, identity, and history. Digital tools can democratize knowledge but also reinforce biases, depending on how they are designed and used.
5. Interdisciplinary Collaboration
Digital humanities are inherently interdisciplinary, bringing together traditional humanities scholars with computer scientists and data analysts. This collaboration leads to new research questions, methods, and forms of knowledge.
Areas where digitization is important:
- research methods
- dissemination
- cultural heritage
- collaboration
- preservation
Content from Data
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- What is data in the humanities?
- What are the distinctions between different types of data?
Objectives
After completing this episode, participants should be able to
- differentiate between analogue data, digitised data, and born-digital data,
- understand how data is categorized, collected, and utilized within humanities research,
- explore the implications of different data types for different research methods and outcomes.
Types of Data
Analogue Data: Analogue data originates in physical, non-digital formats like handwritten documents, photographs, or physical artefacts.
digitised Data: digitised data refers to analogue information that has been converted into digital formats through processes such as scanning, encoding, or transcription. This transition expands the accessibility and usability of analogue resources, facilitating modern research methods. Understanding different aspects of digitised data is critical for recognizing how non-digital resources have been adapted to meet digital needs.
Born-Digital Data: Born-digital data is inherently created in digital environments and exists only in these formats . It includes databases, digital texts, or media files that have never existed in physical, analogue form. This distinction highlights how digital-first practices shape contemporary research in the humanities, emphasizing the real-time creation and accessibility of data through digital platforms.
Exercise
Analogue vs. Digital – What Are We Really Looking At?
This exercise invites you to explore how analogue and digital data differ by looking at a cultural heritage object. It focuses on what happens when physical artworks are made accessible through digital media. Let’s take some data from the Metropolitan Museum of Modern Art’s collection.
Guiding Question
What kind of data are we working with when we interact with digitised cultural objects? What happens to the qualities of analogue objects when they are transformed into digital representations?
Step 1: Observation
Choose a digital image of an object from the Metropolitan Museum of Modern Art’s online collection (or from another digital museum resource). Reflect on the following questions: What kind of object is this originally? What can you observe on the screen? What might be missing compared to experiencing the object in person?
Step 2: Guided Discussion
With the following questions: If the original artwork is analogue (physical), and we’re viewing it on a screen, what kind of data are we really working with? What happens to the object’s materiality when it is digitized? How does digital representation affect our understanding or interpretation? What do we gain, and what do we lose, in this transformation?
Step 3: Reflection
Consider: What qualities of an object are difficult or impossible to capture digitally? Which digital formats (e.g., high-resolution images, 3D models, metadata) attempt to compensate for these limitations? In your own field of study, where do you encounter the analogue-to-digital transformation? How does it affect your research or interpretation?
We’re viewing the painting on a computer screen. Everything we see is displayed digitally. Although the original object is analogue, our interaction with it is entirely digital. The painting has been digitized—converted into data (e.g., pixels, metadata) that can be stored, processed, displayed by computers, shared, searched, and manipulated. We are not interacting with the analogue object itself, but with its digital representation. This transformation allows broader access but also introduces limitations: aspects like scale, texture, or true colour may be lost, and we experience only a digital approximation. Understanding this transformation is key to working with data in the digital humanities and is critical for thinking about how cultural knowledge is shaped by the digital medium.
By analogue data, we mean the physical artefacts in the museum. The museum’s collection includes numerous physical objects such as sculptures, paintings, and other artefacts that exist solely in their original, non-digital form. For instance, the collection of ancient Egyptian art in the Metropolitan Museum comprises approximately 30,000 objects, as you can see here.
By digitised data, we mean for example digitised images. High-resolution photographs of artworks and artefacts, such as paintings, sculptures, and archaeological findings, have been digitised for research and accessibility. These images are accessible through the museum’s online collection database.
Born-Digital Data are some born-digital photographs or videos, as well as digital records and databases of the museum’s collections, including metadata and detailed descriptions of artworks. The museum’s archives include born-digital materials such as exhibition records, curatorial files, and administrative documents created and stored digitally.
Affordances and challenges associated with each data type, and their interactions within the broader research ecosystem:
These types of data are utilized in different ways, each shaping and supporting distinct research practices.
Analogue data, preserved in magazines, archives, or physical collections, provides the foundation for historical and material studies, offering direct engagement with original sources. Analogue data’s tactile and contextual elements are invaluable for understanding its provenance and authenticity. Still, these data are often constrained by access limitations, requiring researchers to travel to specific locations.
digitised data transforms the accessibility of these physical sources, enabling remote access through digital platforms and repositories. This shift democratizes research by bridging geographic barriers and facilitating comparative studies. Additionally, digitization often incorporates metadata and search functionalities, enhancing the discoverability and usability of analogue sources. However, the process of digitization raises concerns about data integrity, potential loss of context, and the prioritization of certain collections over others.
Born-digital data is, by contrast, inherently dynamic, designed for integration into digital environments. It supports collaborative and interdisciplinary research, as it can be shared, updated, and analyzed in real-time. The computational possibilities of born-digital data, including machine learning and data visualization, open new avenues for exploration, particularly in fields like Digital Humanities, data science, and social network analysis. Nonetheless, this type of data also poses challenges, such as ensuring long-term preservation, managing data privacy, and addressing the ephemerality of digital formats.
Moreover, these types of data often interact within hybrid research workflows. For instance, digitised analogue data can be enriched through computational analysis alongside born-digital datasets, creating new layers of insight. Similarly, born-digital data may prompt the re-examination of analogue sources, fostering a cyclical process of discovery and reinterpretation. This interplay highlights the evolving landscape of knowledge production, where diverse data types converge to address complex research questions.
Outcome
How do institutional infrastructures, such as libraries, archives, and data centres, support these processes and navigate the challenges of balancing preservation, access, and innovation?
- Analogue data is preserved in magazines, archives, or physical collections.
- digitised data is a transformation of analogue data into digital form.
- Born-digital data has no analogue representation.
Content from Metadata
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- What is metadata?
- What are major types of metadata?
Objectives
After completing this episode, participants should be able to
- understand metadata basics,
- differentiate metadata from data,
- differentiate the major types of metadata,
- apply metadata concepts to practical challenges,
- recognise the role of metadata in the humanities.
Metadata Types, Functions, and Contexts
Metadata is a form of data that describes other data. Metadata provides meaningful information that makes it easier to find, identify, understand, handle, and preserve the primary data.
Data itself can be structured or “raw,” meaning unprocessed or unstructured. In contrast, metadata is always processed and structured, designed to be understandable by both humans and machines. Metadata serves a functional purpose, such as organising materials in a catalog or enabling the search and retrieval of resources in a database. It helps convey essential attributes of data, such as its origin, time period, and geographic coverage.
There are three major types of metadata:
Descriptive metadata describes a resource for purposes such as discovery and identification. It can include elements such as title, author, date of creation, medium, dimension, and keywords.
Descriptive metadata is crucial for discovering and identifying resources like books, journal articles, or digital archives in humanities disciplines, for cataloguing and analyzing artworks in museum databases or academic studies, and supports historians in locating and studying primary sources.
Structural metadata indicates how composite objects are assembled.
For example, the structural metadata of a digitised medieval manuscript in an online archive defines the hierarchy and organization of the manuscript:
- Page order (e.g., folio 1 recto, folio 1 verso)
- Relationships between sections (e.g., chapters, marginalia, glosses)
- Links between text and corresponding images, such as illuminations or annotations
Administrative metadata provides information to help manage a resource, such as when and how it was created, file type and other technical information, and who can access it. There are several subsets of administrative data, including:
− Rights management metadata, which deals with intellectual property rights − Preservation metadata, which contains information needed to archive and preserve a resource
Administrative metadata is essential for managing the life cycle of resources. For example, rights management metadata informs whether a researcher can legally reproduce an image in a publication, while preservation metadata supports digital preservation practices to protect fragile manuscripts.
Challenge 1:
Go back again to the online resources we reviewed. Find the data to which the metadata relates. Are you able to identify what type of metadata this is?
The objects searchable in the Met Museum’s online collection primarily feature descriptive metadata, such as title, author, date, and size. Administrative metadata is largely limited to the inventory number, though additional administrative (meta)data, potentially sensitive in nature, may remain unpublished. Structural metadata is generally scarce, despite the suitability of many well-documented art and cultural objects for such detailed representation. However, creating structural metadata would require extensive indexing, which is often impractical. Institutions typically prioritise basic cataloguing with minimal metadata, while in-depth cataloguing is frequently undertaken as part of specific projects.
Challenge 2:
Is the book “Alice’s Adventures in Wonderland” data or metadata?
It depends on the context whether it is considered data (the book itself) or metadata (title in a library catalogue).
The distinction between data and metadata often depends on the context in which the information is used. Data and metadata are relative concepts, and what serves as “data” in one scenario may function as “metadata” in another.
For example, the text of “Alice’s Adventures in Wonderland” — its words, chapters, and narrative — is typically considered data when analysing its content, themes, or linguistic features. However, the title “Alice’s Adventures in Wonderland”” is metadata within the context of the book’s cataloguing. In a library catalogue, the title is part of a structured system of metadata used to describe, organise, and enable the discovery of the book (along with other metadata fields like author, publication date, and ISBN).
This relativity highlights the importance of understanding the different levels at which we interact with information. In essence:
- Data refers to the primary subject of study or use (e.g., the full text of the book).
- Metadata refers to information about that data, designed to describe, contextualise, or facilitate its organisation and retrieval (e.g., the title, author, or genre classification).
This interplay between data and metadata underscores the layered nature of information management and the need for precision when working with both.
- Descriptive metadata describes a resource for purposes.
- Structural metadata indicates how composite objects are assembled.
- Administrative metadata provides information to help manage a resource.
Content from Collecting, Storing and Processing Metadata
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- In which formats can data and metadata be stored in a structured way?
- What is a CSV file and how is its content structured?
Objectives
After completing this episode, participants should be able to
- describe the basic structure of a CSV format for storing and processing metadata,
- open and investigate a simple CSV file,
- explain the main difference between an xslx and a csv format.
Introduction to metadata file formats
Question:
Do you know any formats in which data can be stored in a structured way?
An easy way to store data in a structured way is to use a spreadsheet such as Excel.
In order to store metadata and make it usable in other contexts, appropriate formats are required. The most common file formats used to store metadata are XML and JSON. A lot of data is also stored in the more familiar CSV format, as a real-world example will show later.
Interoperability
The advantage of using such a format is the interoperability of the data. This means that the data is collected and stored by one person, but can be opened, processed or merged with other data elsewhere.
Challenge
Open the artworksShort.csv file and the artworksShort.xslx file in your favorite spreadsheet application.
- What do you notice?
- What form does the data have?
- What are the advantages of recording data in tabular format?
- Why is this data interoperable?
- Several parameters are queried when the csv file is opened.
- Some data in the xslx file is formatted with colours and bold and
italic text. You won’t find this in the csv file.
- The data in a spreadsheet is in tabular form.
- The data is broken down into individual fields.
- Contents are named and labelled through the column names.
- The data is in a digital file format that can be edited and shared.
CSV files
The CSV (comma-separated values) format in this example is usually opened as a table in a spreadsheet so that it can be read by humans in a structured way. If you open the format in a text editor, you can see the structure of the file:
ID;artist;title;date
1;Salvador Dalí;The persistence of memory;1931
2;Walker Evans;Allie Mae Burroughs, Wife of a Cotton Sharecropper, Hale County, Alabama;1936
3;Frida Kahlo;Roots;1943
4;Käthe Kollwitz;Mother with Child over her Shoulder;Before 1917
5;Berthe Morisot;The psyche mirror;1876
1;Georgia O’Keeffe;Sky above clouds IV;1965
3;Banksy;Girl with Ballon;2002As you opened the CSV file in a spreadsheet program, some parameters were queried before you could open it. Here’s the reason why:
The data in this particular CSV file is separated by semicolons - the delimiters. Delimiter-separated files are often given a .csv extension, even if the field separator is not a comma, as the example shows. In many files you will find the contents of the data fields enclosed in quotation marks. Records are separated by a line break. The first line often defines the column headers. If these parameters are entered correctly when the file is opened, the data will be transferred to the appropriate fields in the spreadsheet.
The Difference between CSV and XSLX files
An XSLS format allows you to store, format and apply formulas to data in multiple spreadsheets that are stored in a single file. Data is organised into cells, which are arranged in rows and columns. Both the cells and the data values within them can be formatted, including fonts, colours and borders. The data can be manipulated using built-in functions, e.g. for calculation or analysis. It is also possible to visualise the analysed data in spreadsheet software such as Excel.
One of the disadvantages is the limited number of rows and columns - for example 1,048,576 rows and 16,385 columns per worksheet depending on your software version. Other features can depend on the software version as well. Older tables may not always display correctly with the latest version due to a lack of feature compatibility.
The CSV (comma-separated values) format stores tabular data in plain text that can be opened in spreadsheet software. It is therefore readable by both humans and machines. There is always only one table stored in a single file. However, the plain text format allows more data to be stored in a file, making it particularly efficient as it does not store superfluous data such as formatting data. It is therefore suitable for storing and exchanging data between applications or databases.
One of its disadvantages is that it can only store simple tabular data, and not data with more complex structures.
Data Organization
When entering data into spreadsheets, there are a number of issues that need to be considered to ensure that the data can be processed correctly. In addition to the comma-separated fields mentioned above, which can cause problems, there are many other issues. Dates or names are a major source of error. Different spellings can lead to misinterpretation. For example, how do you interpret the date 25-01-11 if it is written in a single field? Or: Which part of a person’s name is the first name and which part is the surname?
Find out more on Data Organization
For further reading see Data Organization in Spreadsheets for Social Scientists
An important part of recording metadata is annotating the data. Take Walker Evans as an example: Annotating - i.e. tagging - him as “artist” or “photographer” allows users to understand the role of this entry in the context of the dataset. In the spreadsheet example, “artist” is one of the column headings.
If you are using a spreadsheet to annotate dates, it may be worth splitting the year, month and day into separate fields to avoid the problem described above. Later you will learn about other ways to display dates correctly.
There are certain data formats that solve some of the problems mentioned here - for example data created with a markup language. Markup languages are used to structure and format text and data in a machine-readable way. They are based on a meta-language called SGML. SGML is a standard for markup languages. It specifies how to define the syntax (rules) for elements, attributes, and document structure in a markup language.
- If you need to format the data and spreadsheet, use the XSLX format
to store and analyse the data.
- If you don’t need to analyse or visualise the data, use an
interoperable format such as CSV to store or share the data.
- It is helpful to annotate the data - for example with headers.
- Be aware of the problems that can occur when annotating data and metadata with, for example, dates or names.
Content from XML
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- What is XML?
- What are the elements of XML?
- How do you annotate data in XML?
Objectives
After completing this episode, participants should be able to
- describe the XML format for storing and processing metadata,
- name syntax rules for a well-formed XML file,
- investigate the structure of a simple XML file,
- write extracted metadata in a simple XML format.
One of the most widely used file formats in the cultural sector is XML (eXtensible Markup Language). It is used to describe, structure, store and transport data. XML refers to the file format as well as to the syntax in which data is recorded: the markup language. By marking up the text with tags, data and metadata can be combined in a single document.
XML Elements
An XML document contains XML elements to structure the data. They are formed using tags in angle brackets and are divided into an opening tag and a closing tag, indicated by a leading slash. The content is placed in between.
The tags are given a name that describes the content:
XML
<photographer>Walker Evans</photographer>
<name>Walker Evans</name>
<artist>Walker Evans</artist>You may be familiar with this structure. The HTML language, which is used to organise web pages, has a similar structure. It is also based on SGML. HTML makes it possible to mark up the typical elements of a text-based document - such as headings, paragraphs, lists or tables - as such on a web page and to structure the page semantically. Unlike HTML, where there are rules for naming tags - such as <h1></h1> for headings - XML tags can be named freely, subject to a few technical rules. This makes it particularly interesting for use in the development of metadata standards and ontologies.
Rules for naming tags1
Names:
- Must start with a letter or underscore.
- Cannot start with the letters xml (or XML, or Xml, etc).
- Can contain letters, digits, hyphens, underscores, and periods.
- Cannot contain spaces.
Best Naming Practices and what to consider:
- Create descriptive names.
- Create short and simple names.
- Avoid - / . / : in the names, e.g. <first-name> (: is reserved for namespaces which have a special function).
- XML tags are case sensitive. The tag
is different from the tag . - XML does not truncate multiple white-spaces.
XML also provides the ability to have comments that are not automatically read:
In XML, all elements must be properly nested, which means that an element opened inside another element must also be closed inside it:
Indentation can be used to make the structure more human-readable, especially if elements’ nesting is deep:
XML
<collection>
<name>MET</name>
<place>collection of the MET in New York</place>
<artist>
<name>Fullname</name>
<dateOfBirth>
<day>Day of Birth</day>
<month>Month of Birth</month>
<year>Year of Birth</year>
</dateOfBirth>
</artist>
</collection>As this example shows, XML documents have a tree structure. They start with the root element and then branch out deeper and deeper. The tag <artist> is called a parent element and the subordinated elements <name> and <dateOfBirth> are child elements. In the deeper level, <dateOfBirth> is the parent element for the tags day, month and year as child elements.
Characters used in the structure of the XML syntax must comply with certain rules. Certain characters, such as “<” meaning “is less than”, must be replaced by a special string so that they won’t cause problems. If you just use “<”, XML understands it as an opening tag and expects it to be closed at some point. To avoid errors in this and similar cases, the character is replaced with an entity reference:
| string | character | meaning | |
|---|---|---|---|
| < | < | less than | |
| > | > | greater than | |
| & | & | ampersand | |
| ' | ’ | apostrophe | |
| " | ” | quotation mark |
Attributes
In XML, as in HTML, tags can also have attributes, which define the content of the tags in more detail. These attributes provide metadata for the element that they refer to. They are named, the content is assigned to them with a =, and they are enclosed in quotation marks:
XML
<title lang="author's original language">Always give the title in the author's language</title>
<commonTitle lang="title as commonly known">Always give the title as it is commonly known</commonTitle>Attributes are often used in a hierarchy to record information that applies to all the underlying data:
The slash here at the end of the tag (self-closing tag) means that the element is empty and self-contained. It is not necessary to write an opening and closing tag if there are no other elements between them. You often see this in XML output when the metadata field is empty.
At the top of an XML document you will often find something called a prolog or declaration:
It is optional, but provides information about the version and encoding2 used. If included, it must be placed at the top of the document above the root element. The XML prolog or declaration does not have a closing tag.
XML documents that conform to all these rules are considered “Well-Formed” XML documents.
Exercise
Open the moma_artworks.csv file. Choose the data of an artwork and write it in the XML format.
- Is there a structure for the data? Can data be collected under a category?
- You can use indentation to create a hierarchy.
XML
<?xml version="1.0" encoding="UTF-8"?>
<artworks>
<artwork>
<title>Green-Blue-Red (for Parkett no. 35)</title>
<artist>
<name>Gerhard Richter</name>
</artist>
<constituentID>4907</constituentID>
<artistBio>
<bio>German, born 1932</bio>
</artistBio>
<nationality>German</nationality>
<beginDate>1932</beginDate>
<endDate>0</endDate>
<gender>male</gender>
<date>1993</date>
<medium>Multiple of oil on canvas</medium>
<dimensions>composition: 11 7/16 × 15 3/4" (29 × 40 cm); sheet: 11 3/4 × 15 3/4" (29.9 × 40 cm)</dimensions>
<creditLine>Riva Castleman Endowment Fund, Lily Auchincloss Fund, and Gift of Parkett</creditLine>
<accessionNumber>110.1998.1</accessionNumber>
<classification>Multiple</classification>
<department>Drawings & Prints</department>
<dateAcquired>1998-03-05</dateAcquired>
<cataloged>Y</cataloged>
<objectID>61953</objectID>
<url>https://www.moma.org/collection/works/61953</url>
<imageURL></imageURL>
<onView></onView>
<height>29.0</height>
<width>40.0</width>
</artwork>
<artwork>
<title>Untitled</title>
<artist>
<name>Blinky Palermo</name>
</artist>
<constituentID>4474</constituentID>
<artistBio>
<bio>German, 1943–1977</bio>
</artistBio>
<nationality>German</nationality>
<beginDate>1943</beginDate>
<endDate>1977</endDate>
<gender>male</gender>
<date>1970</date>
<medium>Dyed cotton mounted on muslin</medium>
<dimensions>6' 6 3/4\" x 6' 6 3/4\" (200 x 200 cm)</dimensions>
<creditLine>Gift of Jo Carole and Ronald S. Lauder</creditLine>
<accessionNumber>650.1997</accessionNumber>
<classification>Painting</classification>
<department>Painting & Sculpture</department>
<dateAcquired>1997-06-02</dateAcquired>
<cataloged>Y</cataloged>
<objectID>78283</objectID>
<url>https://www.moma.org/collection/works/78283</url>
<imageURL>https://www.moma.org/media/W1siZiIsIjE1MTQ0MCJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=c54d00f27ed284be</imageURL>
<onView></onView>
<height>200.0</height>
<width>200.0</width>
</artwork>
<artwork>
<title>Daylight Savings Time</title>
<artist>
<name>Pierre Roy</name>
</artist>
<constituentID>5065</constituentID>
<artistBio>
<bio>French, 1880–1950</bio>
</artistBio>
<nationality>French</nationality>
<beginDate>1880</beginDate>
<endDate>1950</endDate>
<gender>male</gender>
<date>1929</date>
<medium>Oil on canvas</medium>
<dimensions>21 1/2 x 15" (54.6 x 38.1 cm)</dimensions>
<creditLine>Gift of Mrs. Ray Slater Murphy</creditLine>
<accessionNumber>1.1931</accessionNumber>
<classification>Painting</classification>
<department>Painting & Sculpture</department>
<dateAcquired>1931-01-19</dateAcquired>
<cataloged>Y</cataloged>
<objectID>78294</objectID>
<url>https://www.moma.org/collection/works/78294</url>
<imageURL>https://www.moma.org/media/W1siZiIsIjIzMzkzNyJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=74825d4c62cd5a8a</imageURL>
<onView></onView>
<height>54.6</height>
<width>38.1</width>
</artwork>
<artwork>
<title>The Bather</title>
<artist>
<name>Paul Cézanne</name>
</artist>
<constituentID>1053</constituentID>
<artistBio>
<bio>French, 1839–1906</bio>
</artistBio>
<nationality>French</nationality>
<beginDate>1839</beginDate>
<endDate>1906</endDate>
<gender>male</gender>
<date>c. 1885</date>
<medium>Oil on canvas</medium>
<dimensions>50 x 38 1/8" (127 x 96.8 cm)</dimensions>
<creditLine>Lillie P. Bliss Collection</creditLine>
<accessionNumber>1.1934</accessionNumber>
<classification>Painting</classification>
<department>Painting & Sculpture</department>
<dateAcquired>1934-09-23</dateAcquired>
<cataloged>Y</cataloged>
<objectID>78296</objectID>
<url>https://www.moma.org/collection/works/78296</url>
<imageURL>https://www.moma.org/media/W1siZiIsIjQ0NjA2NyJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=c6bd692fa0fe0685</imageURL>
<onView>"MoMA, Floor 2, 2 South"</onView>
<height>127.0</height>
<width>96.8</width>
</artwork>
<artwork>
<title>Syntheses of Naples</title>
<artist>
<name>Enrico Prampolini</name>
</artist>
<constituentID>4720</constituentID>
<artistBio>
<bio>Italian, 1894–1956</bio>
</artistBio>
<nationality>Italian</nationality>
<beginDate>1894</beginDate>
<endDate>1956</endDate>
<gender>male</gender>
<date>before 1930</date>
<medium>Oil on canvas</medium>
<dimensions>39 3/8 x 39 1/2" (100 x 100.3 cm)</dimensions>
<creditLine>Gift of Dr. Julius Spitzer</creditLine>
<accessionNumber>1.1942</accessionNumber>
<classification>Painting</classification>
<department>Painting & Sculpture</department>
<dateAcquired>1941-12-10</dateAcquired>
<cataloged>Y</cataloged>
<objectID>78299</objectID>
<url>https://www.moma.org/collection/works/78299</url>
<imageURL>https://www.moma.org/media/W1siZiIsIjE4NjgzNSJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=9740d0c731c867c2</imageURL>
<onView></onView>
<height>100.0</height>
<width>100.3</width>
</artwork>
</artworks>This is one possible solution. You can choose other ways to structure the data by nesting elements like “artistBio” or “gender” within a parent element like “artist”:
Discussion
Compare your XML file with the other participants’ documents. What do you notice?
- XML is one of the most widely used metadata file formats.
- An XML document contains XML elements to structure the data.
- Attributes provide additional information about elements or groups of elements.
[1]: w3school XML
elements
[2]: For further information see the glossary.
Content from JSON
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- What is JSON?
- How do you annotate data in JSON?
Objectives
After completing this episode, participants should be able to
- describe JSON format for storing and processing metadata,
- investigate and write a simple JSON file.
Another file format in which metadata can be stored, annotated and exchanged is JSON (JavaScript Object Notation). Its syntax is inspired by JavaScript object notation.
JSON Data
JSON data is written as key/value pairs. A key/value pair consists of a key, followed by a colon, followed by a value. The key is the name - the label - for the content in the value field. Keys are always written in quotation marks. How the value is marked depends on its data type. The entire content is enclosed in curly brackets.
Values
Value in a JSON file cannot be:
- a function
- a date (dates are written as strings in double quotes – so be aware of problems that might cause)
- undefined
Different Data Types as Values
| data type | explanation | example as key/value pair |
|---|---|---|
| string | set of characters | “string” : „Can be a sentence or a name or a date and is written in double quotes“ |
| integer | whole number | “integer” : 12 |
| float | floating-point number | “float” : 3.5 |
| boolean | truth value | “boolean” : true/false |
| array | collection of values | “array” : [„Didi“, 35, „Whatever“, true] |
| JSON object | a set of JSON data | “object” : {„name“ : „Kim“, „age“ : 39} |
JSON vs XML
- Both are human and machine readable.
- Both can be structured hierarchically (values within values).
- Both can be parsed and used by many programming languages.
But JSON is shorter than XML and easier to use in data processing. JSON can use arrays, so a set of multiple values can be stored and easily processed within a key, but interpreted as multiple values. XML, on the other hand, allows multiple values to be written in a tag, but they are not processed as such because the contents of a tag are not interpreted as multiple values, even if the data is separated by a comma or other character.
Exercise
Use the artwork that you chose from moma_artwork.csv in the previous exercise and write the data in JSON format this time.
JSON
[{
"Title": "Green-Blue-Red (for Parkett no. 35)",
"Artist": [
"Gerhard Richter"
],
"ConstituentID": [
4907
],
"ArtistBio": [
"German, born 1932"
],
"Nationality": [
"German"
],
"BeginDate": [
1932
],
"EndDate": [
0
],
"Gender": [
"male"
],
"Date": "1993",
"Medium": "Multiple of oil on canvas",
"Dimensions": "composition: 11 7/16 × 15 3/4\" (29 × 40 cm); sheet: 11 3/4 × 15 3/4\" (29.9 × 40 cm)",
"CreditLine": "Riva Castleman Endowment Fund, Lily Auchincloss Fund, and Gift of Parkett",
"AccessionNumber": "110.1998.1",
"Classification": "Multiple",
"Department": "Drawings & Prints",
"DateAcquired": "1998-03-05",
"Cataloged": "Y",
"ObjectID": 61953,
"URL": "https://www.moma.org/collection/works/61953",
"ImageURL": null,
"OnView": "",
"Height (cm)": 29.0,
"Width (cm)": 40.0
},
{
"Title": "Untitled",
"Artist": [
"Blinky Palermo"
],
"ConstituentID": [
4474
],
"ArtistBio": [
"German, 1943–1977"
],
"Nationality": [
"German"
],
"BeginDate": [
1943
],
"EndDate": [
1977
],
"Gender": [
"male"
],
"Date": "1970",
"Medium": "Dyed cotton mounted on muslin",
"Dimensions": "6' 6 3/4\" x 6' 6 3/4\" (200 x 200 cm)",
"CreditLine": "Gift of Jo Carole and Ronald S. Lauder",
"AccessionNumber": "650.1997",
"Classification": "Painting",
"Department": "Painting & Sculpture",
"DateAcquired": "1997-06-02",
"Cataloged": "Y",
"ObjectID": 78283,
"URL": "https://www.moma.org/collection/works/78283",
"ImageURL": "https://www.moma.org/media/W1siZiIsIjE1MTQ0MCJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=c54d00f27ed284be",
"OnView": "",
"Height (cm)": 200.0,
"Width (cm)": 200.0
},
{
"Title": "Daylight Savings Time",
"Artist": [
"Pierre Roy"
],
"ConstituentID": [
5065
],
"ArtistBio": [
"French, 1880–1950"
],
"Nationality": [
"French"
],
"BeginDate": [
1880
],
"EndDate": [
1950
],
"Gender": [
"male"
],
"Date": "1929",
"Medium": "Oil on canvas",
"Dimensions": "21 1/2 x 15\" (54.6 x 38.1 cm)",
"CreditLine": "Gift of Mrs. Ray Slater Murphy",
"AccessionNumber": "1.1931",
"Classification": "Painting",
"Department": "Painting & Sculpture",
"DateAcquired": "1931-01-19",
"Cataloged": "Y",
"ObjectID": 78294,
"URL": "https://www.moma.org/collection/works/78294",
"ImageURL": "https://www.moma.org/media/W1siZiIsIjIzMzkzNyJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=74825d4c62cd5a8a",
"OnView": "",
"Height (cm)": 54.6,
"Width (cm)": 38.1
},
{
"Title": "The Bather",
"Artist": [
"Paul Cézanne"
],
"ConstituentID": [
1053
],
"ArtistBio": [
"French, 1839–1906"
],
"Nationality": [
"French"
],
"BeginDate": [
1839
],
"EndDate": [
1906
],
"Gender": [
"male"
],
"Date": "c. 1885",
"Medium": "Oil on canvas",
"Dimensions": "50 x 38 1/8\" (127 x 96.8 cm)",
"CreditLine": "Lillie P. Bliss Collection",
"AccessionNumber": "1.1934",
"Classification": "Painting",
"Department": "Painting & Sculpture",
"DateAcquired": "1934-09-23",
"Cataloged": "Y",
"ObjectID": 78296,
"URL": "https://www.moma.org/collection/works/78296",
"ImageURL": "https://www.moma.org/media/W1siZiIsIjQ0NjA2NyJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=c6bd692fa0fe0685",
"OnView": "\"MoMA, Floor 2, 2 South\"",
"Height (cm)": 127.0,
"Width (cm)": 96.8
},
{
"Title": "Syntheses of Naples",
"Artist": [
"Enrico Prampolini"
],
"ConstituentID": [
4720
],
"ArtistBio": [
"Italian, 1894–1956"
],
"Nationality": [
"Italian"
],
"BeginDate": [
1894
],
"EndDate": [
1956
],
"Gender": [
"male"
],
"Date": "before 1930",
"Medium": "Oil on canvas",
"Dimensions": "39 3/8 x 39 1/2\" (100 x 100.3 cm)",
"CreditLine": "Gift of Dr. Julius Spitzer",
"AccessionNumber": "1.1942",
"Classification": "Painting",
"Department": "Painting & Sculpture",
"DateAcquired": "1941-12-10",
"Cataloged": "Y",
"ObjectID": 78299,
"URL": "https://www.moma.org/collection/works/78299",
"ImageURL": "https://www.moma.org/media/W1siZiIsIjE4NjgzNSJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=9740d0c731c867c2",
"OnView": "",
"Height (cm)": 100.0,
"Width (cm)": 100.3
}]This is not the only correct way to annotate the data in a JSON file. You are free to choose, e.g., whether you want to name the keys according to the headings in the CSV, or you want to enter the information from each record one-to-one as values. You can also choose other ways to structure the data, for example:
JSON
[{
"artwork" : {"separatePairs" : "containing all information only on the artwork as separate key/value pairs",
"title" : "title",
"artist" : "artist",
"year" : 2025},
"artist" : {"artistInformation" : "containing all information only on the artist",
"ArtistBio": ["Nationality, Lifespan"],
"Nationality": "Somewhere",
"BeginDate": 1000,
"EndDate": 2000,
"Gender": "gender"},
"administrativeData" : {"informationAdData" : "containing all information only on the administrative data of the recording",
"DateAcquired": "1941-12-10",
"Cataloged": "Y",
"OnView": ""}
}]You can use a validator to check that a json file is correct. This checks the syntax of the json for formal errors, e.g., Json Formatter & Validator.
Question
Why are the values containing the artist information created as arrays (recognisable by the square brackets), even though they contain only one value?
There are works of art and objects made by several artists. As this is certainly a common case, the data field for the value is defined as an array in advance, to be able to handle this case and not have to query it separately for each record.
- (Meta)data elements are defined in key/value pairs.
- Keys are strings and appear in quotation marks.
- Values can be strings, numbers (float or integer), boolean, arrays or objects.
- Elements are separated by commas.
- Curly brackets contain objects.
- Square brackets contain arrays.
- In-line comments are not supported.
Content from Introduction to Metadata Standards and Schemas
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- What is a metadata standard?
- What is a metadata schema?
- What is a model?
Objectives
After completing this episode, participants should be able to
- explain the terms metadata standard, metadata
schema and metadata model,
- memorize the basic ideas of standard, schema and model,
- summarize the basic concepts and data relationships for standards,
schemas and models.
Standard, Schema or Model?
The terms metadata standard, metadata schema, and metadata model are often used synonymously. The following is an attempt to differentiate between the terms. However, it must be emphasized that this is not a universal claim; rather, it is intended to facilitate a better understanding of the structures of data standardization, as there are no universally accepted definitions of these terms.
Metadata Standard
A metadata standard is a technical specification that describes how data should be annotated or structured. There are several ways to standardise data. Two of the main concepts will be presented in this lesson. On the one hand, each element or data field is uniquely named (e.g. author, title, etc.) and can be specified by rules in the form of attributes (e.g. data type). On the other hand, a structure for recording the data can be defined in terms of groups or categories, such as administrative, technical and descriptive metadata. Both methods provide a basic description and organisation of the data, thereby standardising it. Of course, a combination of the two is also possible.
There are different standards for different topics and communities. This ensures that, for example, the rules for recording data in an archive or library are taken into account. The provenance principle in archives or the pertinence principle in libraries can be represented in this way.
Example
Metadata structure:
- Administrative metadata
- Descriptive metadata
- Structural metadata
- Technical metadata
Metadata elements:
- creator
- publisher
- date
- rights
- pages
- file format
- title
Metadata elements within a structure:
- Administrative metadata
- publisher
- rights
- Descriptive metadata
- creator
- date
- title
- Structural metadata
- pages
- Technical metadata
- file format
Metadata Schema
A metadata schema is mostly used to structure data within a specific context, and there are countless standards for each discipline or specific purpose. During the development phase of the data structure, an existing metadata standard can be integrated. Its rules are then applied to the metadata fields, which in turn are placed in a larger context.
Imagine you want to describe the photograph of a building. In the metadata, you have an element called “creator”. Whose name would you enter here? The photographer’s or the architect’s? Here, you can add “role”” as a metadata element to further describe the context of the personal data. You might also want to structure the data for the photo and the building it depicts separately to display the information accurately. A schema can map a custom structure or the hierarchy of a collection, as well as define data fields for specific subjects. As a result, a schema places the data in a desired context and establishes the relationships between information contained in it.
Conceptual Model
Conceptual models, also known as semantic data models, are
typically abstractions of real-world entities. They are used to formally
articulate the data of a collection or specialised domain in an abstract
way. An example of such a model is the Entity-Relationship Model, which
describes the relationship between two data entities. For example, the
relationship between the entity of the author “Franz Kafka” and the
entity of the book “The Trial” can be defined by the relationship “has
written”.
The advantage of this relationship is that it allows flexible linking of
data. In addition, the entity “book” can be linked to the entity
“publisher” by the relationship “has published”.
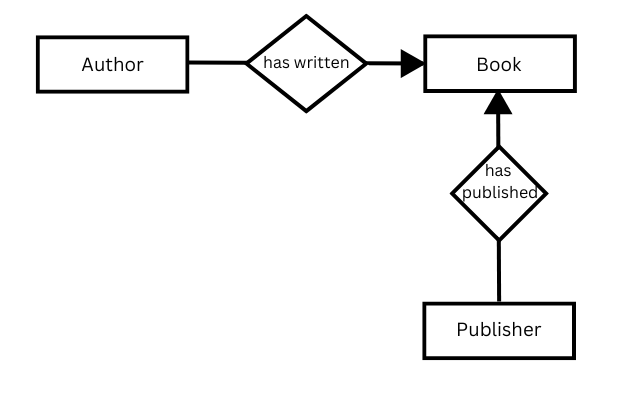
In the conceptual model, data is modelled in the form of triples. A triple consists of a subject, an object and a predicate. The predicate describes the relationship between the subject, the entity to be described, and the object (the entity associated with the subject):
author (subject) has written (predicate) book (object).
An object can become the subject of another triple, and vice versa, as the example above illustrates.
This approach is mainly used in the Semantic Web, where it serves as the basic framework for linked open data. Linked open data aims to achieve the maximum degree of interconnection between data sets. Entities in this context are provided with unique identifiers in the metadata, which in turn represent entities that have their own metadata. To illustrate, an entity can be described by its identifier in the context of the Wikimedia Foundation’s knowledge base, known as “Wikidata”. By establishing these links, the data available in this repository is being used indirectly.
Exercise:
Discuss the following diagram in small groups. What is shown? How is the data linked? Can you think of other data that could be linked?
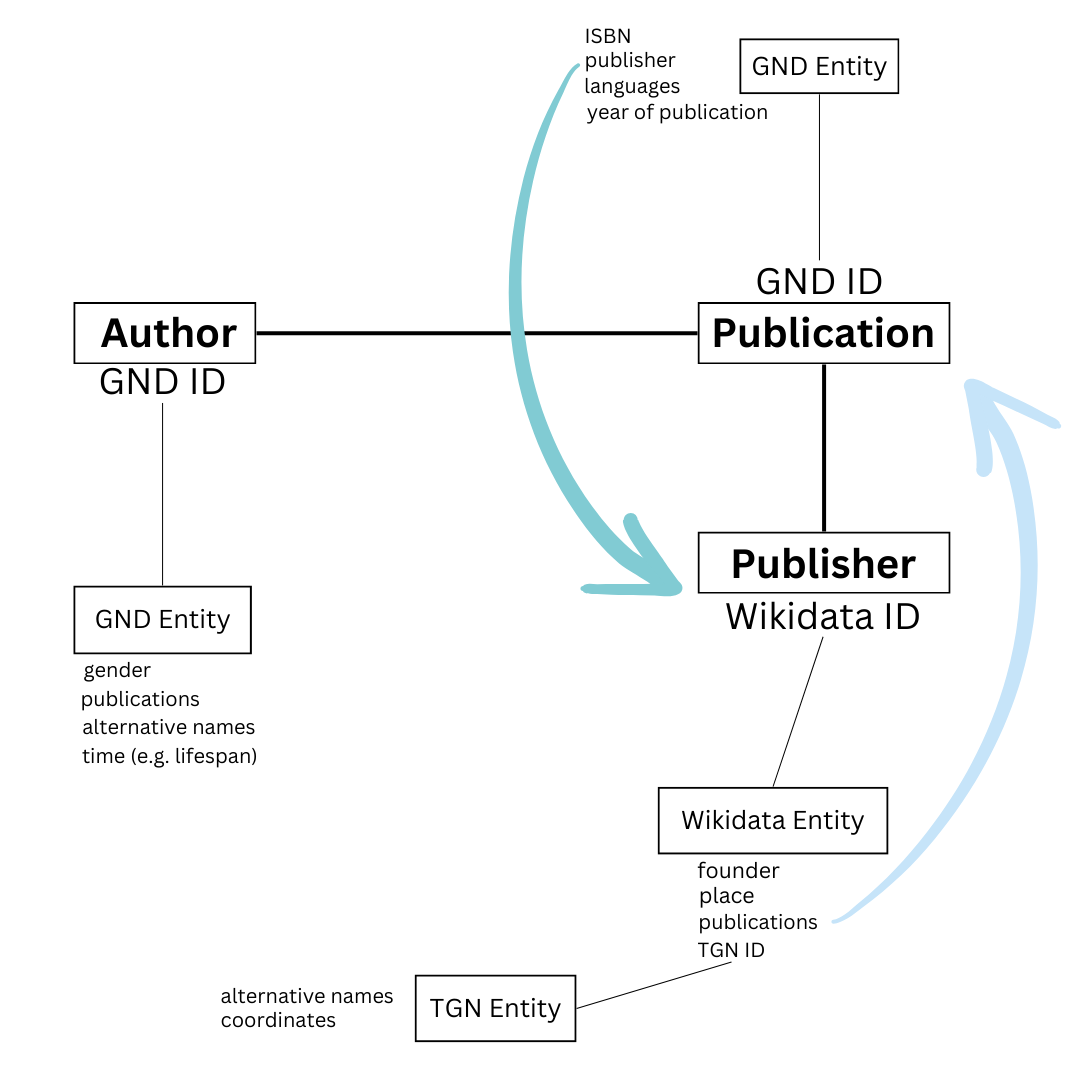
Not only is the name of the author is included as an entity, but also its GND database identifier. The Gemeinsame Normdatei (GND), maintained by the Deutsche Nationalbibliothek (German National Library), is a comprehensive database describing persons, corporations, conferences, geographies, subject headings and works. Within the GND, the author entity is also a metadata entity containing biographical data. Linking these two entities combines their data into a single record, eliminating the need for separate records. The publication also has a record in the GND database, and this entity is linked to all the metadata associated with the publication, such as the year of publication. In this example the publisher has a separate entity in the form of a “Wikidata” record to which it is linked. The metadata in this entity contains information about the publisher’s location, linked to an identifier. In this example this is the TGN ID. The Getty Thesaurus of Geographic Names (TGN) serves as a standard database for geographic names, recording different spellings, including historical ones, as well as coordinates and country affiliation, among other attributes. This creates a network of data that can be expanded as needed, depending on data availability. There are many other data value standards that provide information about entities such as objects, vocabulary, terms, etc. They could all be used to extend the network into a graph.
Data Value Standards
These standards provide controlled vocabularies, thesauri
(hierarchical lists of related terms) and authority files (lists of
standardised names or terms for entities such as authors, artists or
organisations) to ensure consistency in the terms used to describe
resources (e.g. Getty Art & Architecture Thesaurus, Virtual
International Authority File - VIAF).
Value standards are essential for improving discoverability and ensuring
that metadata records are consistent and accurate across different
datasets and systems.
Cultural heritage collections are often characterised by considerable heterogeneity in terms of content, age, retro-digitisation methods and associated data capture processes. There is also considerable variation in the nature and extent of metadata recorded across collections. Differences in data acquisition and storage practices also contribute to this heterogeneity. However, the goal of consolidating collections into online portals for improved visibility and accessibility requires the implementation of data standardisation to the greatest extent possible. It also helps research to ensure comparability across large numbers of objects. Standardising large amounts of data from diverse collections is costly in terms of time, money and human resources, which are often in short supply. For this reason, minimum metadata requirements have been discussed in recent years. A minimum data set developed in Germany is briefly presented here.
The terms metadata standard, metadata schema and metadata model are
often used interchangeably. They can be broadly distinguished as
follows:
- A metadata standard describes the elements or structure of metadata
and is mainly defined for technical implementation.
- A metadata schema provides a structure for metadata within a specific
content, often integrating existing metadata standards.
- A metadata model is an abstract and theoretical model that describes
metadata in its context.
Content from Minimum Record Recommendation
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- What is the Minimum Record Recommendation for Museums and Collections?
Objectives
After completing this episode, participants should be able to
- summarize the basic concept of the Minimum Record Recommendation for Museums and Collections.
Minimum Record Recommendation for Museums and Collections
The recommendation was formulated by the Minimum Record Working Group, which was established in 2022 by the Museum and Media Desks of the German Digital Library (DDB), the Working Group on Digitisation of the „Konferenz der Museumsberatungsstellen in den Ländern“ (KMBL) and digiS Berlin1. The aim of the working group is to contribute the data to the German Digital Library2 and the Europeana online database3. The German Digital Library online database, which aims to make cultural heritage in Germany digitally accessible at any time and free of charge, is an initiative of the German Digital Library. The database brings together the offerings of various museums, collections and archives in Germany through the submission of their data. The Europeana database is the digital cultural portal for Europe’s cultural heritage.
The Minimum Record Recommendation [therefore] specifies the most important data elements for the online publication of object information from museums and collections and provides information on how these elements should be filled in. The “Minimum Record” is the smallest possible intersection of relevant data elements that ensures a minimum level of data quality across most disciplines and museum types. […] The Minimum Record Recommendation is intended to pave the way for smaller and larger museums and collections to publish their data online and to communicate relevant standards in an easy-to-understand, low-threshold approach.4
The Recommendation’s development was based on a comprehensive set of principles and standards that are essential for the management of research data. First and foremost, it incorporates the FAIR principles (findable, accessible, interoperable, re-usable). It also incorporates the CARE principles (collective benefit, authority to control, responsibility, ethics), particularly in the context of colonial studies. The recommendation also takes into account the minimum information requirements of the LIDO standard:
It has been shown that LIDO is not always easy to understand due to its language (XML-based) and structure (high degree of nesting, repeating element sets). In some cases, LIDO - a highly complex and flexible standard - exceeds the specific needs and capacities of museums and collections. The aim of the Minimum Record Recommendation is to take advantage of LIDO’s benefits (structuring, controlled vocabulary integration, broad international acceptance) and to focus on the smallest possible intersection of data elements that are important for online publication across most disciplines and museum types.5
This illustrates the strong interrelationship that underlies many standards, and which we will encounter again in the following chapters.
The record contains a number of mandatory fields. The use of other data fields, such as object description, material, dimensions and so on, is only recommended.
Data elements that are usually populated during data entry:
- Object title or name (mandatory)
- Object type or designation (mandatory)
- Classification (recommended)
- Inventory number (mandatory)
- Object description (recommended)
- Materials (recommended)
- Techniques (recommended)
- Measurements (recommended)
- Event in object history [element set] (mandatory)
- Event type (mandatory)
- Person/corporate body (conditionally mandatory)
- Date (conditionally mandatory)
- Place (conditionally mandatory)
- Subject keyword (recommended)
- Media file [element set] (mandatory)
- Link to media file (mandatory)
- Usage rights of media file (mandatory)
- Rights holder of media file (conditionally mandatory)
- Alternative text (recommended)
Data fields that are usually populated during or after export from the local database system:
- Record ID (mandatory)
- Record language (mandatory)
- Record type (mandatory)
- Repository of object (mandatory)
- Institution providing record (mandatory)
- Media file: type of media file (mandatory)
- Usage rights of metadata record (mandatory)
- Link to published metadata record (recommended)
- Record date (recommended)
Discussion
What do you think about the Minimum Record Recommendation?
- Do you find it helpful?
- Can you imagine filling in all the mandatory fields?
- What might be a challenge?
The Minimum Record Recommendation is an attempt to formulate a minimum set of data fields for the publication of museum collections from the multitude and complexity of existing standards.
[1]: Minimum
Record Recommendation
[2]: Deutsche
Digitale Bibliothek
[3]: Europeana
[4]: Minimum
Record Recommendation
[5]: Why
is the Minimum Record Recommendation LIDO-compliant?
Content from Metadata Encoding & Transmission Standard (METS)
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- What is the Metadata Encoding & Transmission Standard?
- What are its important elements?
Objectives
After completing this episode, participants should be able to
- describe the basic concept of the Metadata Encoding &
Transmission Standard,
- discuss the important elements for structuring data in METS.
METS Metadata Encoding & Transmission Standard
Provided by the Library of Congress, METS is an XML format defined by XML Schema for describing digital collections of objects with metadata. The standard does not specify a name or order for the metadata fields themselves, but serves to structure them in a standardised way. It is often used for long-term preservation. Metadata is added in one of seven domains:
- METS Header: Metadata describing the METS document itself, including such information as creator, editor, etc.
- Descriptive Metadata Section: The section may point to descriptive metadata external to the METS document, or contain internally embedded descriptive metadata, or both.
- Administrative Metadata Section: provides information regarding how the files were created and stored, intellectual property rights, metadata regarding the original source object from which the digital library object derives, and information regarding the provenance of the files comprising the digital library object
- File Section: lists all files containing content which comprise the electronic versions of the digital object.
- Structural Map: It outlines a hierarchical structure for the digital library object, and links the elements of that structure to content files and metadata that pertain to each element.
- Structural Links: to record the existence of hyperlinks between nodes in the hierarchy outlined in the Structural Map.
- Behavioral Section: can be used to associate executable behaviors with content in the METS object.
XML syntax:
XML
<mets>
<metsHdr/><!-- METS Header -->
<dmdSec/><!-- Descriptive Metadata Section -->
<amdSec/><!-- Administrative Metadata Section -->
<fileSec/><!-- File Section -->
<structMap/><!-- Structural Map -->
<structLink/><!-- Structural Links -->
<behaviorSec/><!-- Behavioral Section -->
</mets>Exercise Part I
Use the example from the XML exercise and assign the metadata elements to the structure of the METS standard.
Using the first artwork record from the example file a XML with a METS structure could look like that:
XML
<mets>
<metsHdr>
<creator>Moma</creator>
<editor>me</editor>
<creationdate>today</creationdate>
</metsHdr>
<dmdSec>
<artwork>
<title>Green-Blue-Red (for Parkett no. 35)</title>
<date>1993</date>
<medium>Multiple of oil on canvas</medium>
<dimensions>composition: 11 7/16 × 15 3/4" (29 × 40 cm); sheet: 11 3/4 × 15 3/4" (29.9 × 40 cm)</dimensions>
<department>Drawings & Prints</department>
<artist>
<name>Gerhard Richter</name>
<constituentID>4907</constituentID>
<artistBio>
<bio>German, born 1932</bio>
</artistBio>
<nationality>German</nationality>
<beginDate>1932</beginDate>
<endDate>0</endDate>
<gender>male</gender>
</artist>
</dmdSec>
<amdSec>
<creditLine>Lillie P. Bliss Collection</creditLine>
<accessionNumber>1.1934</accessionNumber>
<dateAcquired>1998-03-05</dateAcquired>
<cataloged>Y</cataloged>
<objectID>61953</objectID>
</amdSec>
<fileSec>
<url>https://www.moma.org/collection/works/78296</url>
<imageURL>https://www.moma.org/media/W1siZiIsIjQ0NjA2NyJdLFsicCIsImNvbnZlcnQiLCItcmVzaXplIDEwMjR4MTAyNFx1MDAzZSJdXQ.jpg?sha=c6bd692fa0fe0685</imageURL>
<onView>"MoMA, Floor 2, 2 South"</onView>
</fileSec>
<structMap/>
<structLink/>
<behaviorSec/>
<onView></onView>
</mets>Exercise Part II
You can find examples for structured data in the METS standard on the website of the Library of Congress. What do you notice?
You can figure out that:
- In many examples the MODS standard is used within the METS
structure.
- The last sections are often missing or do not contain much data.
- The amdSec contains technical information on the technical means of
digitisation such as camera or scanner and their settings.
- The amdSec is sometimes divided into further sections, e.g., rights
and technical data.
METS serves as a container for structuring metadata. The metadata fields are usually integrated into the METS structure in a specific standard for the individual fields and their order. These include standards such as Cublin Core, MODS, or MARC.
Content from Dublin Core Metadata Element Set
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- What is the Dublin Core Metadata Element Set (DC)?
- What is the difference between simple and qualified Dublin Core?
Objectives
After completing this episode, participants should be able to
- identify basic elements from the Dublin Core Metadata Element
Set,
- differentiate between a simple Dublin Core Set and a qualified set.
Dublin Core Metadata Element Set
The Dublin Core is a simple metadata standard. First published as a standard by the Dublin Core Metadata Initiative in 1998, the simple version of the set consists of 15 core elements for describing a resource:
- Contributor
- Coverage
- Creator
- Date
- Description
- Format
- Identifier
- Language
- Publisher
- Relation
- Rights
- Subject
- Title
- Type
All fields are optional, can appear multiple times, and, unlike other metadata standards or schemas, can appear in any order. Dublin Core defines the metadata fields themselves, but not the structure for them, which is why it is often combined with structuring standards such as METS.
Exercise
You have a photograph by Johan Hagemeyer. It is called “Albert Einstein, Pasadena”. The photograph is of Albert Einstein. It was taken in 1931 and loaned to the Museum in 1962. It is from the photographer’s estate. Albert Einstein lived from 1879 to 1955 and was 52 years old when the photograph was taken. The photographer, Johan Hagemeyer, lived from 1884 to 1962 and the photo was taken in Pasadena. The location is New York. The photograph measures 24.6 × 18.7 cm. The mount measures 45.6 × 35.4 cm.
You can find the object in the MET collection. View the specifications of the elements on the website if you are unsure about how to annotate.
What information would you include in each metadata field and
why?
Is there any information you are missing to fill in the fields? If so,
which ones and why?
Discuss in small groups.
- contributor: MET (as a custodian and managing institution)
- coverage: New York (as place of the custodian and managing institution)
- creator: Johan Hagemeyer (as photographer)
- date: 1931 (as museum submission date or record entry date (unknown here))
- description: portrait of Albert Einstein
- format: 24.6 × 18.7 cm (foto) or 45.6 × 35.4 cm (full size with mount)
- identifier: missing information
- language: en (RFC 4646 standard)
- publisher: MET
- relation: other fotos of Johan Hagemeyer or images with similiar topic
- rights: © 2013 Jeanne Hagemeyer – All Rights Reserved
- source: missing information
- subject: portrait, Albert Einstein
- title: Albert Einstein, Pasadena
- type: Gelatin silver print
This could be one of many possible solutions.
Discussion
What did you discuss? What were the issues?
After all, how do we know which date is meant? The date of creation or of submission? The original DC terms have been extended to make the information about the data more precise.
Qualified Dublin Core
First, qualifiers were introduced. A qualifier describes an element more precisely.
A simple Dublin Core element looks like this:
dc.date
dc describes the namespace (in this case Dublin Core - you can read more about namespaces in the XML Schema chapter) and date describes the element. Both can now be extended by a qualifier, which specifies the element, e.g.,:
dc.relation.hasversion or dc.relation.isversionof
Exercise
Take a closer look at the date element. You can find a list of all authorised qualifiers for date elements on the Dublin Core Website. What qualifiers would you use for the date elements for Johan Hagemeyer’s photo of Albert Einstein?
- dc.date.created: 1931
- dc.date.submitted: 1962
- dc.date.copyrighted: 2013
- dc.date.issued: date the image was digitaly issued on the web collection for example
DCMI Metadata Terms
In 2022 the Dublin Core Metadata Initiative published an extended set of elements.
Included are the fifteen terms of the Dublin Core™ Metadata Element Set (also known as “the Dublin Core”) plus several dozen properties, classes, datatypes, and vocabulary encoding schemes. The “Dublin Core” plus these extension vocabularies are collectively referred to as “DCMI metadata terms” (“Dublin Core terms” for short). These terms are intended to be used in combination with metadata terms from other, compatible vocabularies in the context of application profiles.1
In addition, there are clarifications, e.g. for the date in the form of dcterms:dateAccepted, or new fields like dcterms:abstract.
Terms:
| abstract | accessRights | accrualMethod | accrualPeriodicity | accrualPolicy |
| alternative | audience | available | bibliographicCitation | conformsTo |
| contributor | coverage | created | creator | date |
| dateAccepted | dateCopyrighted | dateSubmitted | description | educationLevel |
| extent | format | hasFormat | hasPart | hasVersion |
| identifier | instructionalMethod | isFormatOf | isPartOf | isReferencedBy |
| isReplacedBy | isRequiredBy | issued | isVersionOf | language |
| license | mediator | medium | modified | provenance |
| publisher | references | relation | replaces | requires |
| rights | rightsHolder | source | spatial | subject |
| tableOfContents | temporal | title | type | valid |
Discussion
Take a look at the extended elements. You will find several date elements.
Do you agree with the mapping presented in the solution of the last
exercise?
Why not?
Which element would you choose?
You can find descriptions of the elements in the User
Guide.
When we talk or read about Dublin Core, we often notice that what used to be called a (metadata) field is now called an element in Dublin Core. You will often find that the definitions of terms overlap - as described above for standard, schema, and model. When you read the term element from now on, it refers to the data field to which content is assigned when data is captured. Think XML. The element is identified by tags, with the value in between. This combination is used to describe an area of the ingested resource.
- The Dublin Core Standard provides a simple Set of 15 elements as well as a extend set with additional properties, classes, datatypes, and vocabulary encoding schemes.
- All fields are optional, not mandatory, can appear multiple times, and can appear in any order. Dublin Core defines the metadata fields themselves, but not the structure for them.
- The Dublin Core Standard is often used in combination with metadata terms.
[1]: DCMI Metadata Terms
1↩︎
Content from Resource Description Framework (RDF)
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- What is the Resource Description Framework (RDF)?
- How can information be linked using triples and URI?
Objectives
After completing this episode, participants should be able to
- describe the basics of the Resource Description Framework (RDF),
- name the elements of a triple,
- find URI for RDF triple elements and create RDF statements.
RDF was originally conceived by the World Wide Web Consortium (W3C) as a standard for describing metadata. It is now considered a fundamental building block of the Semantic Web and is similar to the classical methods for modeling concepts, such as the Entity-Relationship Model mentioned in the introduction.
Data in RDF are statements about resources. These statements are modeled as triples. The set of triples forms a (mathematical) graph and is called an RDF model.
XML
<subject/><predicate/><object/>
<artist>Frida Kahlo></artist><creator>is creator of</creator><artwork>The two fridas</artwork>The subject and predicate are always resources. This means that they are entities with an extended set of information. The object can be either a resource or a literal. Literals are strings that can be interpreted using a specified data type like boolean values, numbers, or dates. Unique identifiers (e.g. URI) are used to identify resources.
A Uniform Resource Identifier (URI) is an identifier consisting of a string of characters used to identify an abstract or physical resource. They are built in a similar way as a web address (URL). The aforementioned GND or Wikidata IDs are examples. Different sources can be linked together using the URI. Remember the graphic in the introduction.
The predicate is also defined by a URI. This is possible, for example, when the relationship is defined by a metadata standard. The metadata fields of the standards have their own URI. The relationship between an artist and her artwork can be modeled using the Dublin Core element “creator”.
<https://www.wikidata.org/wiki/Q5588><http://purl.org/dc/terms/creator><https://www.wikidata.org/wiki/Q3232010>This example means exactly the same as the previous example: Frida Kahlo is creator of “The two Fridas” by using the identifier of Wikidata and Dublin Core.
Technically, RDF can be implemented in several formats, including JSON-LD and RDF/XML - two special formats of JSON and XML for RDF.
Exercise
Take a closer look at the Wikidata resource of Frida Kahlos painting “The two Fridas”. Can you find an alternative way of describing the predicate instead of using Dublin Core?
creator
property:
The information listed in Wikidata for an entity is all labeled with
properties such as location, genre, creator etc. These properties
themselves have an identifier and are therefore standardized. All
paintings can be modeled in a consistent way. The creator property can
be used similiar to the Dublin Core element of creator.
Exercise
Use wikidata to create a triple for the following statements:
1) Michelangelo is the creator of the Pietà.
2) Michelangelo was born in Caprese Michelangelo.
3) The Pietà is located in the St. Peter’s Basilica.
<https://www.wikidata.org/wiki/Q5592><https://www.wikidata.org/wiki/Property:P170><https://www.wikidata.org/wiki/Q235242>
<https://www.wikidata.org/wiki/Q5592><https://www.wikidata.org/wiki/Property:P19><https://www.wikidata.org/wiki/Q52069>
<https://www.wikidata.org/wiki/Q235242><https://www.wikidata.org/wiki/Property:P276h><ttps://www.wikidata.org/wiki/Q12512>- RDF is a standard model for data interchange on the Web.
- Statements are modeled as triples. Using URI, these triples link data (and thus all the information behind it) and form a (mathematical) graph.
Content from XML Schema
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- What is an XML schema?
- What are the basic elements of an XML schema?
- What is an XML Schema used for?
Objectives
After completing this episode, participants should be able to
- identify the basic elements of an XML Schema,
- recognise the basic structure,
- investigate a simple XML Schema.
As you have learned there are standards for annotating data in the Humanities. To ensure that data is properly standardized and interoperable — allowing it to be imported into, for example, cultural heritage databases — technical schemas are used. In the humanities and cultural studies, XML Schema is a common choice. There are different schema languages to express XML Schema. While it is not the only option, the XML Schema Definition (XSD) is widely used to define the structure, elements, and technical rules of an XML document, thereby establishing consistent annotation guidelines. The filename extension is .xsd.
XSD (XML Schema Definition)
By using the XML-based XML Schema Definition you can define:
- the elements and attributes of an XML document
- the number and order of child elements
- data types and default or fixed values for elements and attributes
It is characterised by the use of a schema tag as the container element for the whole document:
The prefix „xs“ or “xsd” indicates the namespace for the Schema. Remember not to use : in XML tags. Since the colon is a meta character with a reserved meaning, do not use it anywhere except when referencing namespaces.
Namespaces
A namespace contains a set of rules and is defined in the XSD file. Other, existing namespaces can also be included in a certain namespace. The rules defined by existing namespaces are also referenced in the XML document.
The namespace mechanism for XML data has been developed by the W3 Consortium1. A namespace is a set of rules that provides specifications for XML elements and attributes. For example, it describes how elements and attributes are named or used. A namespace can be technically stored in the form of an xsd file or in the form of theoretical documentation. Technical specifications can be requirements for data types or minimum or maximum values. Documentation usually describes contextual relationships or rules for using controlled vocabularies or thesauri. Specifications from the documentation may be technically incorporated into the schema. Otherwise, they may be found as comments in the file.
Example from LIDO Schema2 for the gender of an actor with additional human-readable notes:
XSD
<xsd:element name="genderActor" type="lido:textComplexType" minOccurs="0" maxOccurs="unbounded">
<xsd:annotation>
<xsd:documentation>Definition: The sex of the individual.</xsd:documentation>
<xsd:documentation>How to record: Data values: male, female, unknown, not applicable. Repeat this element for language variants only.</xsd:documentation>
<xsd:documentation>Notes: Not applicable for corporate bodies.</xsd:documentation>
</xsd:annotation>
</xsd:element>The xs:annotation is a container in which additional information can be embedded. When xs:documentation is used within the container, the information is processed in a human readable way. If xs:appinfo is used within it, it means that information is machine-readable.
Namespaces are given for two reasons: First, they define elements and attributes more precisely, especially when they have different meanings in different sources and specifications from different standards need to be combined. Consider the problem of dates and names. They are a very common element and should be defined precisely. How should the date be recorded? As a period of time or as an ISO value? Are first and last names recorded separately? Since there may be different rules in each standard, but they may refer to the same field name, namely “date” or “name”, it is important to specify the source of the rules.
Secondly, they group together all the elements and attributes of an XML application so that software can easily recognise them.
A namespace is assigned in the header of the file by using xmlns as an attribute and a URI as the content.
The xmlns specification and the URI behind it refer to the W3 consortium namespace for an XML Schema as the standard for the entire document. All elements and attributes are defined according to this namespace. The URI (Uniform Resource Identifier) serves as a unique identifier to reference the specifications, it is usually a web address (URL).
Where multiple standards are used, or parts of other schemas are adopted, the namespaces should be prefixed in order to identify which elements or attributes belong to which standard:
XSD
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:xlink="http://www.w3.org/1999/xlink">In the file, the prefix refers to the standard used for that element or attribute. The example above also uses the xlink namespace. This specification defines the XML Linking Language (XLink) version 1.1, which allows elements to be inserted into XML documents to create and describe links between resources.
When specifying multiple standards, if no prefix is specified for a standard, that standard is the default specification for the entire document and all elements without a prefix refer to that standard.
In addition, when creating an xsd file for a specially developed standard, a targetNamespace is specified. This is the name of the namespace, the technical details of which are defined in this xsd file, and which will then be referenced in the XML document.
XSD
<xs:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="lbacao"
xmlns:lc="lbacao"
elementFormDefault="qualified"
attributeFormDefault="unqualified">The default namespace in this example is the xsd namespace. This file creates a new namespace: the lbacao namespace. All elements that do not refer to the xsd namespace would be prefixed with lc.
Other namespaces can also be imported into the schema with the following specification, allowing additional software (validators) to check compliance with this standard:
XSD
<xs:import namespace="http://www.w3.org/XML/1998/namespace" schemaLocation="http://www.w3.org/2001/03/xml.xsd">The schemaLocation refers directly to the associated Schema - the XSD file - the specifications of which are adopted for the document. Special software (validators) can be used to check whether an XML document conforms to the technical rules specified in an XSD file.
Simple Element
A simple XML element is defined in the Schema by the specification xs:element and the attributes name and type at least.
For example, we can specify that a place is always called “place” and that the character type of the content is a string. This specification prevents the tag from sometimes being called “place”, sometimes “location” or even “city”:
This defines the <place> XML tag such as <place>New York</place>.
Content restrictions
Content restrictions for a simple element can be set using so called facets. They are used to define acceptable values for XML elements or attributes:
XSD
<xs:element name="age">
<xs:simpleType>
<xs:restriction base="xs:integer">
<xs:minInclusive value="0"/>
<xs:maxInclusive value="120"/>
</xs:restriction>
</xs:simpleType>
</xs:element>With these restrictions for a datafield “age”, only values from 0 to 120 are allowed in the XML.
You can also use an enumeration constraint to limit the content to a set of values:
XSD
<xs:element name="color">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="blue"/>
<xs:enumeration value="red"/>
<xs:enumeration value="green"/>
</xs:restriction>
</xs:simpleType>
</xs:element>Using xs:pattern you can set restrictions on a series of numbers or letters. There are other constraints for values in XML, e.g., whiteSpace or length:
Restrictions for Datatypes
| Constraint | Description |
|---|---|
| enumeration | Defines a list of acceptable values |
| fractionDigits | Specifies the maximum number of decimal places allowed. Must be equal to or greater than zero |
| length | Specifies the exact number of characters or list items allowed. Must be equal to or greater than zero |
| maxExclusive | Specifies the upper bounds for numeric values (the value must be less than this value) |
| maxInclusive | Specifies the upper bounds for numeric values (the value must be less than or equal to this value) |
| maxLength | Specifies the maximum number of characters or list items allowed. Must be equal to or greater than zero |
| minExclusive | Specifies the lower bounds for numeric values (the value must be greater than this value) |
| minInclusive | Specifies the lower bounds for numeric values (the value must be greater than or equal to this value) |
| minLength | Specifies the minimum number of characters or list items allowed. Must be equal to or greater than zero |
| pattern | Defines the exact sequence of characters that are acceptable |
| totalDigits | Specifies the exact number of digits allowed. Must be greater than zero |
| whiteSpace | Specifies how white space (line feeds, tabs, spaces, and carriage returns) is handled |
A simple element contains only one piece of information. No other elements can be nested within it, nor can content information be stored in additional attributes.
ComplexType
You will often encounter complexType in metadata schemas. This allows the element (later data field) to be defined much more precisely. Using this type, it is possible, for example, to create a group with child elements and to assign attributes to elements.
XSD
<xs:element name="object">
<xs:complexType name="objectType" abstract="true">
<xs:sequence>
<xs:element name="creator" type="xs:string" minOccurs="1"/>
<xs:element name="title" type="xs:string"/>
<xs:element name="date" type="xs:date"/>
<xs:element name="medium" type="xs:string"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="creator" abstract="true">
<xs:sequence>
<xs:element name="name" type="xs:string" maxOccurs="1"/>
<xs:element name="dateOfBirth" type="xs:date"/>
<xs:element name="dateOfDeath" type="xs:date"/>
</xs:sequence>
</xs:complexType>
</xs:element>The above is suggested for the definition of an object, e.g. in cultural heritage. Data fields are defined for the object itself, such as title and creator or medium. At least one creator must be specified in the block for the object. The xs:sequence element (called “indicator”) specifies that the child elements must appear in the specified order. Each child element can occur from 0 to any number of times. In addition, the creator’s details are recorded in the second block, together with the life data. Only one creator’s name may be entered in this block. So if there are multiple creators, each will have their own details in a separate block.
XSD provides more indicators to order the elements or to define the occurrence of elements:
Order indicators, used to define the order of the elements, treated as tags:
- All - The all indicator specifies that the child elements can appear in any order, and that each child element must occur only once.
- Choice - The choice indicator specifies that either one of the child elements of choice can occur.
- Sequence - The sequence indicator specifies that the child elements must appear in a specific order.
XSD
<xs:element name="artist">
<xs:complexType>
<xs:all>
<xs:element name="firstname" type="xs:string"/>
<xs:element name="lastname" type="xs:string"/>
</xs:all>
</xs:complexType>
</xs:element>Occurrence indicators, used to define how often an element can occur, treated like attributes:
- maxOccurs
- minOccurs
XSD
<xs:element name="object">
<xs:complexType name="objectType" abstract="true">
<xs:sequence>
<xs:element name="creator" type="xs:string" minOccurs="1" maxOccurs="3"/>
<!-- minimum one creator has to be added, maximum three can be added -->
<xs:element name="title" type="xs:string" maxOccurs="1"/>
<!-- only one title can be added -->
</xs:sequence>
</xs:complexType>
</xs:element>Group indicators, used to define related sets of elements, treated as tags:
- Group name
- attributeGroup name
XSD
<xs:group name="artistgroup">
<xs:sequence>
<xs:element name="firstname" type="xs:string"/>
<xs:element name="lastname" type="xs:string"/>
<xs:element name="nationality" type="xs:string"/>
</xs:sequence>
</xs:group> It is also possible to assign further attributes to the elements of a complexType. To do this, the attribute itself is created in the form of a simple element and assigned to the corresponding element to which it is to be applied.
XSD
<!-- attribute covers the object element -->
<xs:element name="object" type="string">
<xs:complexType name="objectType" abstract="true">
<xs:element name="title" type="string" maxOccurs="1"/>
<xs:attribute name="lang" type="string" default="EN"/>
</xs:complexType>
</xs:element>
<!-- attribute only for the place element within the archiv element -->
<xsd:complexType name="archiv">
<xsd:sequence>
<xsd:element name="aufbewahrungsort" type="xsd:string" /><!-- depository -->
<xsd:element name="ort"><!-- place -->
<xsd:complexType>
<xsd:attribute name="gndid" type="lc:GNDID" />
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>In the first example above, a language attribute is defined that is applied to the entire element. If the language is not specified, the default value is ‘English’. In the second example, the attribute is defined as a child of the “place” element, and is therefore only valid for that element.
Instead of a default value, the value can also be fixed:
It should be noted that all attributes are optional by default when creating the XML element, unless the use of the attribute is specified as required:
If an attribute is allowed but should not be specified in more detail, the anyAttribute element is used:
XSD
<xs:element name="creator">
<xs:complexType>
<xs:sequence>
<xs:element name="firstname" type="xs:string"/>
<xs:element name="lastname" type="xs:string"/>
</xs:sequence>
<xs:anyAttribute/>
</xs:complexType>
</xs:element>Now the creator can have any attribute in the XML, like e.g. an identifier or an alternative name.
Creating a customized type
You can also create an individual type for elements and attributes:
XSD
<xsd:simpleType name="tGNDID"><!-- GND identifier -->
<xsd:restriction base="xsd:string">
</xsd:restriction>
</xsd:simpleType>
<xsd:complexType name="tHistoricalPerson">
<xsd:all>
<xsd:element name="typ" type="xsd:string" />
<xsd:element name="name" type="xsd:string" />
</xsd:all>
<xsd:attribute name="gndid" type="lc:tGNDID" />
</xsd:complexType>
<xsd:complexType name="tUrkunde">
<xsd:sequence>
<xsd:element name="aussteller" type="lc:tHistoricalPerson" /><!-- author/creator of charter →
</xsd:sequence>
</xsd:complexType>In the simpleType the requirement for a GND identifier is set as a string. The defined type “tGNDID” is used as an attribute in the complexType for the historical personality. The complexType for the historical personality is then used again as a type for the element “aussteller” in the complexType “rUrkunde”.
The XML output would look like this:
XML
<urkunde>
<aussteller gndid="https://d-nb.info/gnd/2001630-X">
<typ>corporation</typ>
<name>University of Marburg</name>
</aussteller>
</urkunde> The methods presented can also be nested in each other:
XSD
<xsd:complexType name="tArchiv">
<xsd:sequence>
<xsd:element name="aufbewahrungsort" type="xsd:string" /><!-- depository -->
<xsd:element name="ort"><!-- place -->
<xsd:complexType>
<xsd:attribute name="gndid" type="lc:tGNDID" />
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>The element “ort” itself is another complexType nested within the complexType “tArchiv”. This is done to assign a special attribute only to this element.
An XML that conforms to a Schema is called valid. It should not be confused with well-formed, which refers to compliance with fundamental XML rules.
Exercise
The example below shows the complexType from a real draft xsd for a charter collection. Add the indents so that the elements are nested correctly as shown in the examples.
XSD
<xsd:complexType name="tUrkunde">
<xsd:sequence>
<xsd:element name="id" type="xsd:string" /> <!-- identifier -->
<xsd:element name="ausstellungsdatum" type="xsd:string" /><!-- date of issue -->
<xsd:element name="datierung"> <!-- dating --><!-- format: yyyy-mm-dd:yyyy-mm-dd -->
<xsd:complexType>
<xsd:attribute name="von" type="xsd:date" />
<xsd:attribute name="bis" type="xsd:date" />
</xsd:complexType>
</xsd:element>
<xsd:element name="aussteller" type="lc:tHistoricalPerson" /><!-- author/creator of charter -->
<xsd:element name="mitsiegler" type="lc:tSimpleHistoricalPerson" minOccurs="0" maxOccurs="unbounded" /><!-- sealer-->
<xsd:element name="ausstellungsort" type="lc:tOrt" /><!-- place of issue -->
<xsd:element name="archiv" type="lc:tArchiv" />
<xsd:element name="siegel"> <!-- seal -->
<xsd:complexType>
<xsd:attribute name="urspr" type="xsd:nonNegativeInteger" /><!-- number of original seals -->
<xsd:attribute name="erha" type="xsd:nonNegativeInteger" /><!-- number of preserved seals -->
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>XSD
<xsd:complexType name="tUrkunde">
<xsd:sequence>
<xsd:element name="id" type="xsd:string" /> <!-- identifier -->
<xsd:element name="ausstellungsdatum" type="xsd:string" /><!-- date of issue -->
<xsd:element name="datierung"> <!-- dating --><!-- format: yyyy-mm-dd:yyyy-mm-dd -->
<xsd:complexType>
<xsd:attribute name="von" type="xsd:date" />
<xsd:attribute name="bis" type="xsd:date" />
</xsd:complexType>
</xsd:element>
<xsd:element name="aussteller" type="lc:tHistoricalPerson" /><!-- author/creator of charter -->
<xsd:element name="mitsiegler" type="lc:tSimpleHistoricalPerson" minOccurs="0" maxOccurs="unbounded" /><!-- sealer-->
<xsd:element name="ausstellungsort" type="lc:tOrt" /><!-- place of issue -->
<xsd:element name="archiv" type="lc:tArchiv" />
<xsd:element name="siegel"> <!-- seal -->
<xsd:complexType>
<xsd:attribute name="urspr" type="xsd:nonNegativeInteger" /><!-- number of original seals -->
<xsd:attribute name="erha" type="xsd:nonNegativeInteger" /><!-- number of preserved seals -->
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>It is more difficult to create a valid XML from an xsd file:
Advanced Exercise
Write an XML file that matches the sample xsd file. To validate the XML you can use the validator. Of course, you can find another validator to check for differences. What notes do you get if the XML is not valid? Are they helpful?
XML
<?xml version="1.0" encoding="utf-8" ?>
<!-- Author: Mathias Gutenbrunner, University Library Marburg
draft as part of the Marburger Urkundenrepositorium - Datenbank des CAO und LBA
https://urkundenrepositorium.uni-marburg.de/home
project website = https://www.uni-marburg.de/de/fb09/deutsche-philologie-des-mittelalters/forschung/marburger-urkundenrepositorium
August 2021
edited by Corinna Berg, Marburg Center for Digital Culture and Infrastructure, Philipps University of Marburg
as part of the HERMES project https://hermes-hub.de/; development of an introduction to metadata standards
March 2025 -->
<!-- Changes:-->
<!-- deleted original comments-->
<!-- added new comments with translations -->
<lba_cao xmlns="lbacao"
xmlns:lc="lbacao">
<urkunde>
<id/>
<ausstellungsdatum/>
<datierung von="1855-01-31" bis="1855-01-31"/>
<aussteller gndid="">
<typ/>
<name/>
</aussteller>
<mitsiegler gndid=""/>
<ausstellungsort gndid=""/>
<archiv>
<aufbewahrungsort/>
<ort gndid=""/>
<institution gndid=""/>
<signatur/>
<vorbesitzer/>
</archiv>
<siegel urspr="3" erha="1"/>
</urkunde>
</lba_cao>As you can see, most of the fields are empty, but some data needs to be added. Since the xsd namespace is referenced, its rules must apply. The dating element has the “from” and “to” attributes which use xs:date as the type. xs:date is specified in the following form “YYYY-MM-DD” and all components are required. Therefore, any date in this format must be added in the XML. The element “seal”, which annotates the number of original and preserved seals, has the type xs:nonNegativeInteger. This type is defined by a number equal to or greater than 0, so a number must be specified here as well.
There are other methods of defining conditions for an XML document in an XML Schema. You can find references to these in this lesson under “More” –> “References” at the top of the lesson.
Question
Did you try to add content to the element “datierung”? If you do, the validator will not accept the XML as correct. Can you imagine why it is not correct to fill in a content like <datierung>2025-03-25:2025-04-01</datierung>? Did you get a note using the validator?
The feedback from the validator would look something like this:
Cvc-complex-type.2.1: Element ‘datierung’ Must Have No Character Or Element Information Item [children], Because the Type’s Content Type Is Empty.
The element “datierung” has no content. It is only defined by its attribute which have to be used. It is called an empty element within a complexType.
- XML Schema is helpful to describe allowed document content. It is the “grammar” for XML.
- It uses XML syntax. If you are familiar with this language you can use it easily.
- An XML that conforms to a Schema is called valid.
- It is easy to validate the correctness of data of an XML by using a validator.
- Your Schema can be reused in other Schemas as well as you can reuse other Schemas.
- You can create your own data types derived from the standard types of xs:schema.
[1]: [The World Wide Web Consortium (W3C)](https://www.w3schools.com/xml/xml_elements.asp>](https://www.w3.org/)
The consortium develops standards and guidelines for World Wide Web
technologies. There you can find all the specifications for XML and XML
schema as well as many more.
[2]: LIDO – Lightweight Information Describing Objects is an XML
harvesting schema. The LIDO schema is intended for delivering metadata,
for use in a variety of online services, from an organization’s online
collections database to portals of aggregated resources, as well as
exposing, sharing, and connecting data on the web, LIDO schema.