Introduction to Metadata Standards and Schemas
Last updated on 2025-04-29 | Edit this page
Overview
Questions
- What is a metadata standard?
- What is a metadata schema?
- What is a model?
Objectives
After completing this episode, participants should be able to
- explain the terms metadata standard, metadata
schema and metadata model,
- memorize the basic ideas of standard, schema and model,
- summarize the basic concepts and data relationships for standards,
schemas and models.
Standard, Schema or Model?
The terms metadata standard, metadata schema, and metadata model are often used synonymously. The following is an attempt to differentiate between the terms. However, it must be emphasized that this is not a universal claim; rather, it is intended to facilitate a better understanding of the structures of data standardization, as there are no universally accepted definitions of these terms.
Metadata Standard
A metadata standard is a technical specification that describes how data should be annotated or structured. There are several ways to standardise data. Two of the main concepts will be presented in this lesson. On the one hand, each element or data field is uniquely named (e.g. author, title, etc.) and can be specified by rules in the form of attributes (e.g. data type). On the other hand, a structure for recording the data can be defined in terms of groups or categories, such as administrative, technical and descriptive metadata. Both methods provide a basic description and organisation of the data, thereby standardising it. Of course, a combination of the two is also possible.
There are different standards for different topics and communities. This ensures that, for example, the rules for recording data in an archive or library are taken into account. The provenance principle in archives or the pertinence principle in libraries can be represented in this way.
Example
Metadata structure:
- Administrative metadata
- Descriptive metadata
- Structural metadata
- Technical metadata
Metadata elements:
- creator
- publisher
- date
- rights
- pages
- file format
- title
Metadata elements within a structure:
- Administrative metadata
- publisher
- rights
- Descriptive metadata
- creator
- date
- title
- Structural metadata
- pages
- Technical metadata
- file format
Metadata Schema
A metadata schema is mostly used to structure data within a specific context, and there are countless standards for each discipline or specific purpose. During the development phase of the data structure, an existing metadata standard can be integrated. Its rules are then applied to the metadata fields, which in turn are placed in a larger context.
Imagine you want to describe the photograph of a building. In the metadata, you have an element called “creator”. Whose name would you enter here? The photographer’s or the architect’s? Here, you can add “role”” as a metadata element to further describe the context of the personal data. You might also want to structure the data for the photo and the building it depicts separately to display the information accurately. A schema can map a custom structure or the hierarchy of a collection, as well as define data fields for specific subjects. As a result, a schema places the data in a desired context and establishes the relationships between information contained in it.
Conceptual Model
Conceptual models, also known as semantic data models, are
typically abstractions of real-world entities. They are used to formally
articulate the data of a collection or specialised domain in an abstract
way. An example of such a model is the Entity-Relationship Model, which
describes the relationship between two data entities. For example, the
relationship between the entity of the author “Franz Kafka” and the
entity of the book “The Trial” can be defined by the relationship “has
written”.
The advantage of this relationship is that it allows flexible linking of
data. In addition, the entity “book” can be linked to the entity
“publisher” by the relationship “has published”.
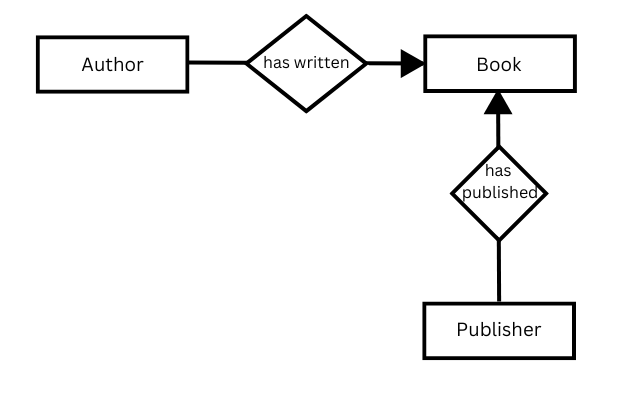
In the conceptual model, data is modelled in the form of triples. A triple consists of a subject, an object and a predicate. The predicate describes the relationship between the subject, the entity to be described, and the object (the entity associated with the subject):
author (subject) has written (predicate) book (object).
An object can become the subject of another triple, and vice versa, as the example above illustrates.
This approach is mainly used in the Semantic Web, where it serves as the basic framework for linked open data. Linked open data aims to achieve the maximum degree of interconnection between data sets. Entities in this context are provided with unique identifiers in the metadata, which in turn represent entities that have their own metadata. To illustrate, an entity can be described by its identifier in the context of the Wikimedia Foundation’s knowledge base, known as “Wikidata”. By establishing these links, the data available in this repository is being used indirectly.
Exercise:
Discuss the following diagram in small groups. What is shown? How is the data linked? Can you think of other data that could be linked?
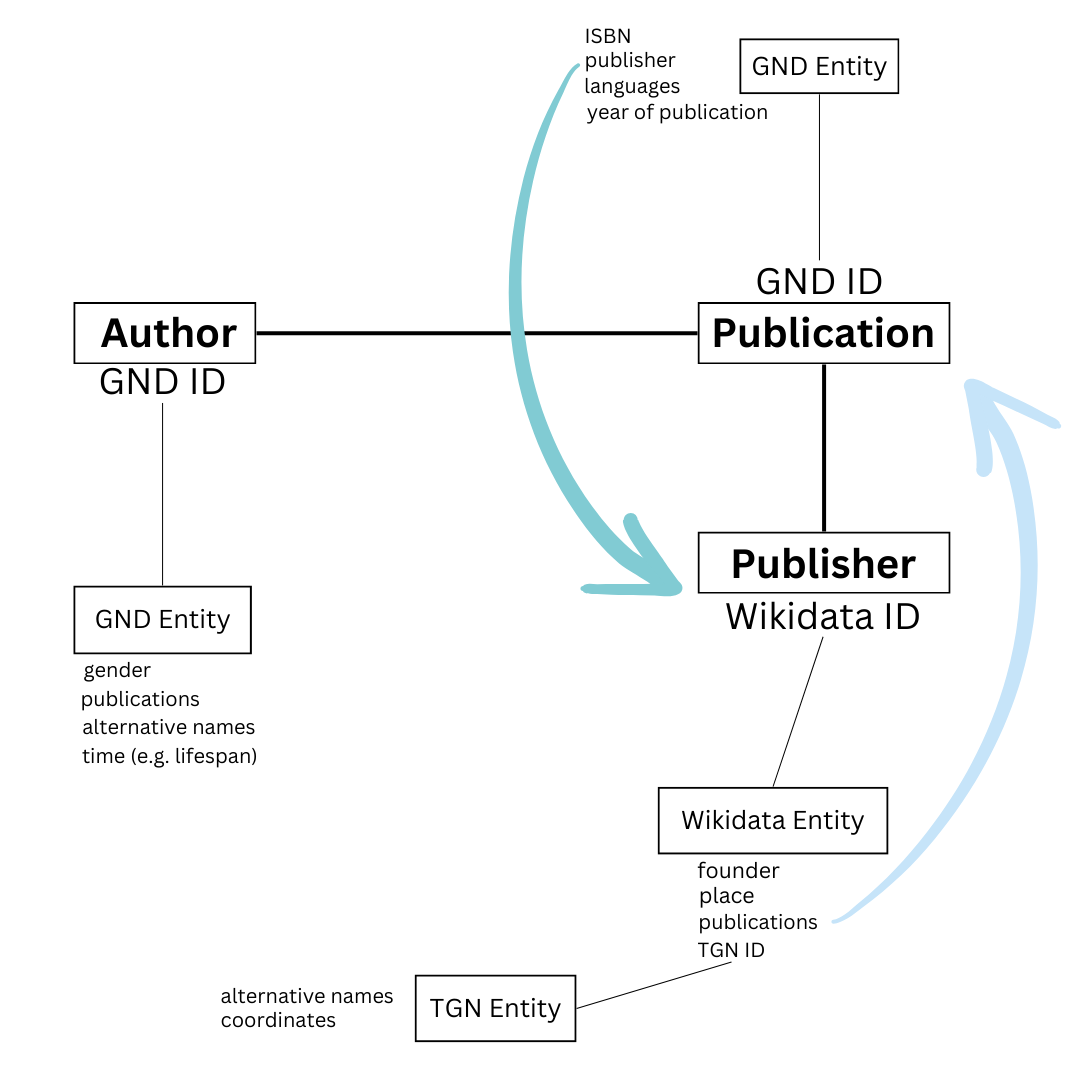
Not only is the name of the author is included as an entity, but also its GND database identifier. The Gemeinsame Normdatei (GND), maintained by the Deutsche Nationalbibliothek (German National Library), is a comprehensive database describing persons, corporations, conferences, geographies, subject headings and works. Within the GND, the author entity is also a metadata entity containing biographical data. Linking these two entities combines their data into a single record, eliminating the need for separate records. The publication also has a record in the GND database, and this entity is linked to all the metadata associated with the publication, such as the year of publication. In this example the publisher has a separate entity in the form of a “Wikidata” record to which it is linked. The metadata in this entity contains information about the publisher’s location, linked to an identifier. In this example this is the TGN ID. The Getty Thesaurus of Geographic Names (TGN) serves as a standard database for geographic names, recording different spellings, including historical ones, as well as coordinates and country affiliation, among other attributes. This creates a network of data that can be expanded as needed, depending on data availability. There are many other data value standards that provide information about entities such as objects, vocabulary, terms, etc. They could all be used to extend the network into a graph.
Data Value Standards
These standards provide controlled vocabularies, thesauri
(hierarchical lists of related terms) and authority files (lists of
standardised names or terms for entities such as authors, artists or
organisations) to ensure consistency in the terms used to describe
resources (e.g. Getty Art & Architecture Thesaurus, Virtual
International Authority File - VIAF).
Value standards are essential for improving discoverability and ensuring
that metadata records are consistent and accurate across different
datasets and systems.
Cultural heritage collections are often characterised by considerable heterogeneity in terms of content, age, retro-digitisation methods and associated data capture processes. There is also considerable variation in the nature and extent of metadata recorded across collections. Differences in data acquisition and storage practices also contribute to this heterogeneity. However, the goal of consolidating collections into online portals for improved visibility and accessibility requires the implementation of data standardisation to the greatest extent possible. It also helps research to ensure comparability across large numbers of objects. Standardising large amounts of data from diverse collections is costly in terms of time, money and human resources, which are often in short supply. For this reason, minimum metadata requirements have been discussed in recent years. A minimum data set developed in Germany is briefly presented here.
The terms metadata standard, metadata schema and metadata model are
often used interchangeably. They can be broadly distinguished as
follows:
- A metadata standard describes the elements or structure of metadata
and is mainly defined for technical implementation.
- A metadata schema provides a structure for metadata within a specific
content, often integrating existing metadata standards.
- A metadata model is an abstract and theoretical model that describes
metadata in its context.