Content from Introduction
Last updated on 2025-05-02 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- What is the purpose of quantitative data analysis in the humanities?
- When is it meaningful to use quantitative data analysis in humanities research?
- What kinds of operations can be performed in quantitative data analysis?
- How can these operations be performed using Python programming?
Objectives
- Learn the basic principles and methods of quantitative data analysis for the humanities, regardless of your programming experience
- Understand which aspects of different types of datasets can be analyzed quantitatively in humanities research
- Learn how to perform basic analyses on various types of data using Python
- Understand the fundamental principles of writing Python scripts
1.1. Why take this lesson?
This lesson is designed for absolute beginners in digital humanities research. Its goal is to help humanities scholars understand when, why, and how programming can be a valuable tool for data analysis in their work.
By the end of this lesson, you will have learned the basic principles of data analysis with a focus on quantitative research in the humanities using Python. You will be better equipped to determine whether incorporating programming and quantitative methods is meaningful for analyzing your research data. You’ll also be able to evaluate whether digitizing, processing, and publishing existing analog data could benefit your own research and contribute to the broader scholarly community.
1.2. Where does this lesson fit within the broader spectrum of the so-called “digital humanities”?
In the field commonly known as digital humanities, there are generally two major directions you can pursue:
Work at a GLAM institution (Gallery, Library, Archive, Museum), where you digitize texts, images, and objects, and create or enrich digital catalogs for them. In this area, skills such as data management, knowledge of metadata standards, and understanding the FAIR principles are particularly valuable.
Analyze data gathered by yourself, other individuals, or institutions to derive insights that go beyond the capacity of human time or intellect due to the large volume of data. This is the domain of data analysis for humanities research — and this is where we will focus.
Critical Reflection
Although the term “digital scholarship” is becoming increasingly widespread and popular, I avoid using it for several reasons:
What exactly does “digital” mean in this context? Does simply using a computer to create text, images, diagrams or tables transform “analog” scholarship into a “digital” one?
Is “digitality” — however it’s defined in this context — a method, a tool, or something that could give rise to entirely new areas of study, such as the so-called “digital humanities”?
Instead of the vague term “digital scholarship,” I prefer to use “quantitative data analysis.” By “quantitative data analysis,” I refer to a range of methods, including:
- Counting
- Comparing
- Searching
- Pattern recognition
- Classification
- Graphical representation
Quantitative data analysis is a task that can be automated using a computer. It can be performed with existing software designed for specific analysis tasks or by writing your own code using a programming language. In this lesson, we will be taking the second approach, using Python.
1.3. When is it legitimate to practice quantitative data analysis?
In humanities research, quantitative data analysis is only logical and legitimate when:
It reveals new insights: This method should uncover information that was previously unknown. If your research merely confirms what is already well-established, it lacks value. For example, we already know that women have historically been underrepresented in the documentation of human achievements. If we take a book on the history of art, create a list of all the artists mentioned, count how many are women, and conclude that female artists are less frequent in the book than male artists, our effort provides no new knowledge.
The data is too extensive for manual analysis: The data to be analyzed is so vast that it is either impossible for human intellect to process it in a reasonable time frame, or it would require an impractical amount of resources for individuals to analyze it. For instance, counting how many of the 50 country names in a list belong to African Countries does not require programming; it can easily be done by an individual. However, analyzing large datasets, like millions of records, would require quantitative methods.
Caution!
Avoid the temptation to overuse “digital analysis”! In today’s academic environment, there is a temptation to include “digital analysis” in grant proposals or PhD theses simply to make them sound modern and sophisticated. It’s crucial not to fall into this trap and produce work that, in the end, won’t be meaningful or taken seriously. Remember: merely adding a table or graph to your research doesn’t automatically make you a digital humanist or a quantitative data analyst. Always think of the points above and ask yourself whether it is insightful and meaningful to perform quantitative data analysis using programming or software and call it “research with digital methods”.
1.4. What do we do, when we perform quantitative data analysis?
Types of Data in Digital Humanities
Data used for quantitative analysis can take various forms, including:
- Tabular data (containing text, numbers, dates, etc.)
- Text
- Images
- Sound
- Audiovisual data
Workflow for Quantitative Humanities Research
When conducting quantitative research in the humanities using Python, the typical workflow involves the following steps:
- Acquiring the data
- Initiating a Python script
- Loading the data into the script
- Performing operations such as exploring and cleaning the data as well as counting, comparing, searching, pattern recognition, classification, or visual representation
- Generating new knowledge from these processes
- Documenting the insights gained
- Presenting the insights in the context of a scientific research
Required Knowledge for Data Analysis in the Humanities
To effectively analyze data in quantitative humanities research, it is important to have the following knowledge:
- A solid understanding of the data itself and how computers interpret and process it
- Clear insight into the specific aspects of the data to be analyzed and the type of knowledge or insights one aims to extract
- The ability to interact with computers to produce meaningful results — this requires proficiency in a programming language or familiarity with relevant software tools.
Determine whether the type and volume of your research data, as well as your research question, justify the use of quantitative data analysis. Avoid performing quantitative data analysis merely for the sake of having done something “digital”!
If you choose to pursue quantitative data analysis, consider what insights you want to extract from your data and how you can achieve this using Python programming.
Content from Analyzing Tabular Data
Last updated on 2025-11-18 | Edit this page
Estimated time: 248 minutes
Overview
Questions
- What quantitative analysis operations can be performed on tabular data?
- How can these operations be translated into Python code?
Objectives
- Learn how to initiate the analysis of tabular data
- Understand which aspects of a tabular dataset can be analyzed quantitatively
- Learn to break down the analysis into smaller tasks, think in terms of computer logic by writing pseudocode, and translate these tasks into code
- Learn using the Python library Pandas for analyzing tabular data
- Learn using the Python library Plotly for visualizing tabular data
Let’s take on the role of an art historian in this chapter and analyze the MoMA dataset introduced in the Summary and Setup section. We’ll assume that we are completely unfamiliar with the dataset, its contents, structure, or potential usefulness for our research. The first step would be to look at this dataset and get familiar with its shape, dimension and different aspects. This initial stage of investigation is known as exploratory data analysis.
To begin, we first need to open an IDE (Integrated Development Environment), select the programming language we’ll use, and load the dataset into the environment to start working with it. In this case, we’ll be using Jupyter Notebook as our IDE and Python as our programming language.
Step 1 - Importing the Necessary Python Libraries
Modern computers operate using only ones and zeros — binary code. These binary digits can be combined to represent letters, numbers, images, and all other forms of data. At the most fundamental level, this is the only type of information a computer can process.
However, when you’re writing code to analyze data or build applications, you don’t want to start from scratch — managing raw binary data or even working solely with basic characters and numbers. That would be extremely time-consuming and complex. Fortunately, others have already done much of this foundational work for us. Over the years, developers have created collections of pre-written code that simplify programming. You can think of these collections as toolboxes containing functions and methods that perform complex tasks with just a line or two of code. In Python, these toolboxes are called libraries.
A function is a reusable block of code that performs a specific task. You write it once and can use it multiple times. Think of it like a kitchen recipe: you follow the same steps every time you want to bake a cake. Functions help make your code cleaner, shorter, and easier to manage.
A method is just like a function, but it “belongs” to something — usually an object like a string, list, or number. You use methods to perform actions on those objects.
An argument is a value you give to a function or method so it can do its job using that value.
When you define a function, you can set it up to accept input values.
These inputs are called parameters. When you actually
call the function and give it real values, those are called arguments.
For example, in the following code, I am defining a function called
greet. The function takes the name of a person and says
hello to that person. Here, name is a parameter, whereas
Basma is an argument:
Some Python libraries come built into the language, while others must
be installed separately. Most external libraries can be easily installed
via the terminal using a
tool called pip.
Many Python libraries have quirky or creative names — part of the fun
and culture of the programming world! For example, there’s a library
called BeautifulSoup for working with web data, and another
called pandas for data analysis. Sometimes the name hints
at the library’s purpose, and sometimes it doesn’t — but you’ll get used
to them over time. As you gain experience, you’ll learn what each
library is for, the tools it provides, and when to use them.
To use a library in your code, you first need to ensure it is
installed on your computer. Then, you must import it into your script.
If the library’s name is long or cumbersome, you can assign it a shorter
alias when importing it. For instance, in the example below, the
pandas library is imported and abbreviated as
pd. While you’re free to choose any abbreviation, many
libraries have common conventions that help make your code more readable
to other programmers. In the case of pandas,
pd is the widely recognized standard.
Step 2 - Loading the Data into Your Code
Understand the data type
The MoMA dataset we will be working with is stored in a
.csv file. Go ahead and download it from the link provided
in the Summary and Setup section.
CSV stands for “comma-separated values”. When you double-click to open the file, the name makes perfect sense: it contains information arranged in rows, with each value in a row separated by a comma. Essentially, it’s a way to represent a table using a simple text file.
Each line in a CSV file corresponds to a row in the table, and each comma-separated value on that line represents a cell in the row. The first line often contains headers — the names of the columns — which describe what kind of data is stored in each column. For instance, a CSV file containing student information might include headers like “Name”, “Age”, “Grade”, and “Email”.
Because CSV files are plain text, they’re easy to create and read using basic tools like text editors or spreadsheet programs. They’re also widely supported by programming languages and data analysis tools, making them a popular and convenient format for storing and exchanging tabular data.
The data you want to analyze is typically stored either locally on your computer or hosted online. Regardless of where it’s located, the first step in working with it is to load it into your code so you can analyze or manipulate it.
Store the data in a variable
When you load data into your code, you should store it in a
variable. A variable functions like a container that can
contain any type of data that you think of. For example, I can create a
variable called a_number and store a number in it, like
this:
I can also store a string (a sequence of characters, including
letters, numbers, and other symbols) in a variable, which I’ll call
a_string, like this:”
PYTHON
a_string= "This is a string, consisting of numbers (like 13), letters and other signs!"
a_stringNotice that you should put the value of the string inside double or single quotes, but you shouldn’t do it for numbers.
When naming a variable, note that:
- Only letters (a-z, A-Z), digits (0-9), and underscores (_) are allowed.
- The name cannot start with a digit.
- No spaces or special characters (like !, @, #, etc.) are allowed.
- Variable names are case-sensitive. For example,
myvarandMyVarare two different variables. - You cannot use Python reserved keywords like:
if,else,for,class,return, etc. as variable names.
You can either assign a value to a variable directly in your code, as you just did, or you can load data that already exists on your computer or online, and store it in the variable. This is what we are going to do right now:
PYTHON
data_path= 'https://raw.githubusercontent.com/HERMES-DKZ/Python_101_humanities/main/episodes/data/moma_artworks.csv'You already know that CSV files actually represent tabular data. To
make our .csv file look like a table and become more
readable and easier to work with, we are going to load it into a
DataFrame.
DataFrames are powerful table-like data structures that can be
created and manipulated using the pandas library, which we
have previously imported into our code. A DataFrame organizes data into
rows and columns, similar to a spreadsheet or database table. Each
column in a DataFrame has a name (often taken from the header row of the
CSV file), and each row represents an individual record or
observation.
DataFrames are especially useful because they allow us to apply powerful functions and methods that simplify working with structured data. Whether you’re analyzing trends, generating summaries, or preparing data for visualization, DataFrames provide a convenient and flexible way to manage your data.
In the following code snippet, we use the read_csv()
function from pandas to load the contents of the CSV file
into a DataFrame. This function reads the file and automatically turns
it into a DataFrame. In this example, I am passing only one argument to
the read_csv() function: the address of the
.csv file that I want to load. I have already saved this
address in the variable data_path. moma_df is
the variable where we store the resulting DataFrame. Once the data is in
a DataFrame, we can easily explore it, filter rows, select specific
columns, clean the data, and perform many types of analysis.
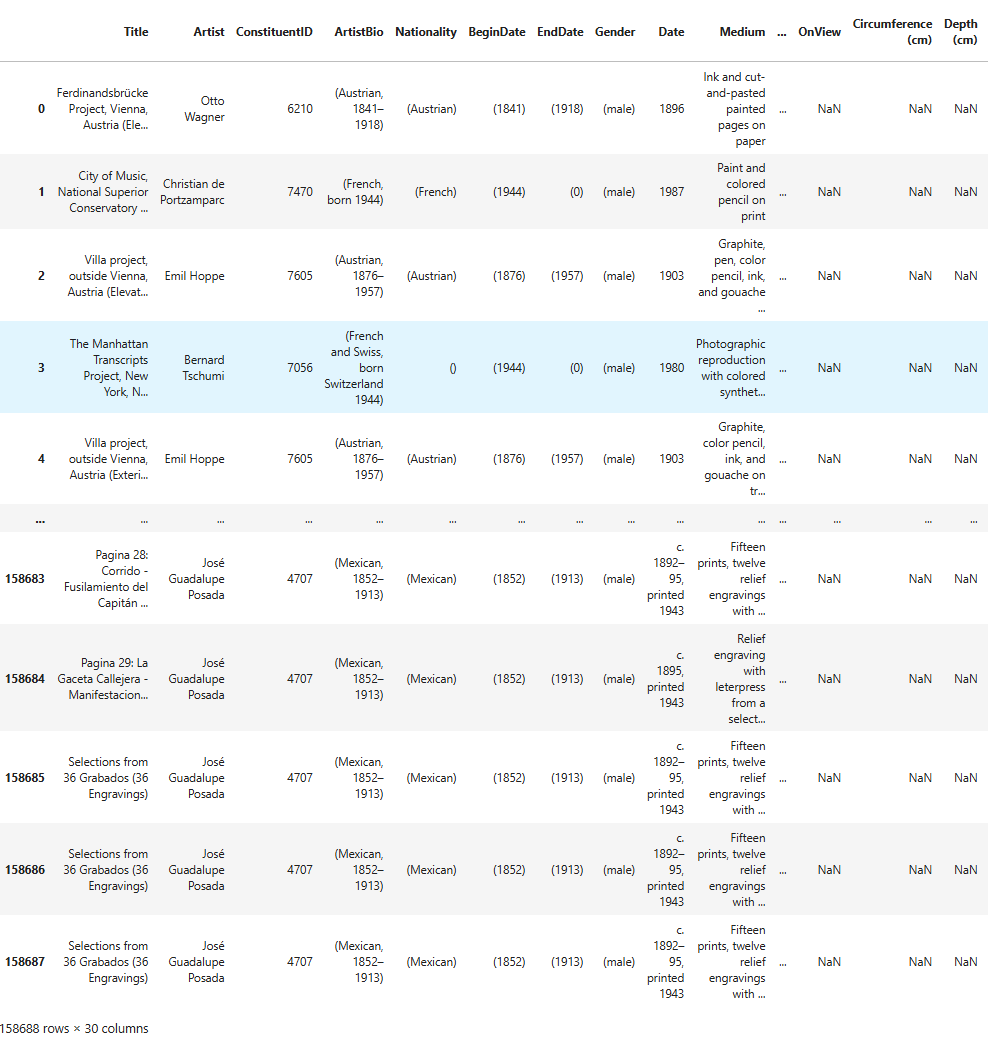
As you can see, this is a large DataFrame, containing 158,688 rows
and 30 columns. For now, we’re only interested in viewing the first few
rows to get a quick overview of its structure — specifically the column
names and the types of values stored in each column. To do this, we’ll
use the DataFrame’s .head() method, like so:
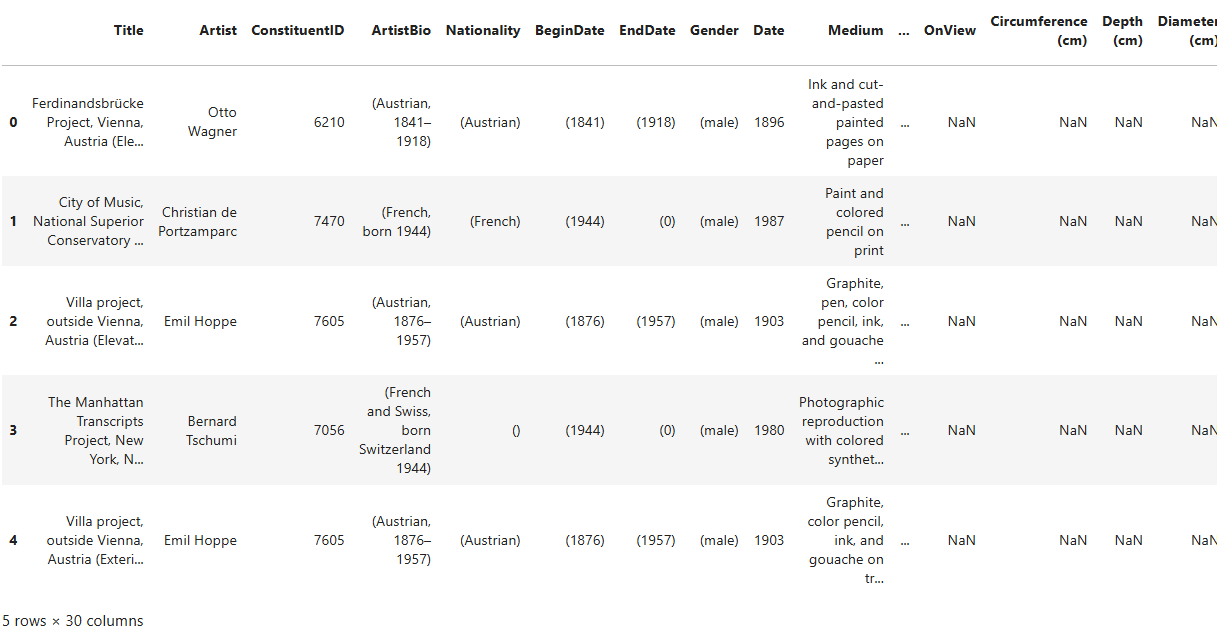
.head() is a method, which means it’s a type of function
that’s associated with a specific object — in this case, a DataFrame.
Like regular functions, methods can accept arguments placed within the
parentheses that follow them. If you don’t provide one,
.head() will return the first five rows by default. If you
pass a number (e.g., moma_df.head(2)), it will return that
many rows from the top of the DataFrame.
Writing pseudocode
By now, you can see that writing code follows a clear and logical workflow. As a beginner, it’s good practice to start by writing pseudocode — a rough outline of your steps in plain, natural language — before translating it into actual code. This helps you plan your approach and stay focused on the logic behind each step.
For example, the steps we’ve taken so far might look like this in pseudocode:
- Import the necessary libraries.
- Save the file path where the data is stored in a variable.
- Load the data into the program from that path.
- Convert the data into a table format that’s easier to explore.
- Display only the first few rows of the table to avoid overwhelming output.This pseudocode translates into the following Python code, which brings together all the lines we’ve written so far:
This dataset contains several aspects that can contribute to research in art history. We will perform three distinct processes — counting, searching, and visualizing — which, as mentioned earlier, could potentially aid in quantitative humanities research. After completing each step, we will analyze the results and discuss whether they provide meaningful insights for scientific research or if they lack scientific significance.
Step 3 - Counting and Searching
You can count all or a selected group of data points in a DataFrame.
To start, let’s get an overview of the counts and data types present in
the DataFrame. To do this, we’ll use the .info() method on
the DataFrame:
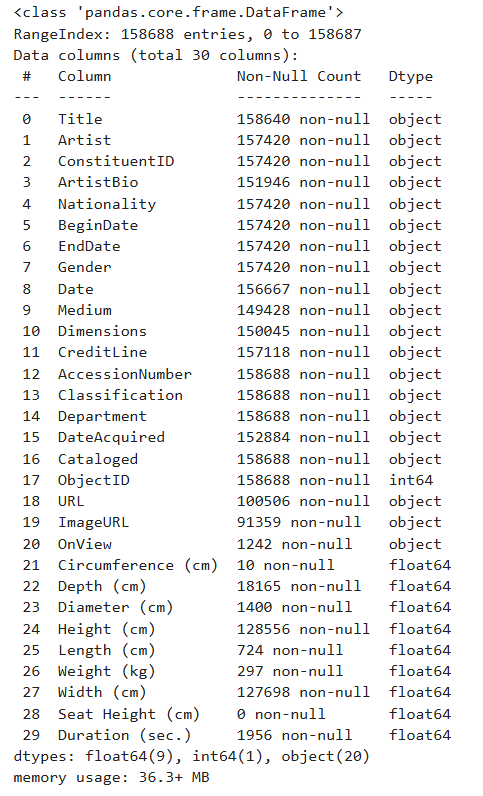
This method provides valuable information about the DataFrame in a tabular format.
Insights from the .info()
Method
In the first column of the resulting table, you can see the names and numbers of all the columns in the DataFrame. As shown here, the first column, “Title”, is numbered as “0”. REMEMBER: In Python, indexing and counting always start from zero. This concept is important to keep in mind when working with lists, strings, Series, DataFrames, dictionaries, and other data structures.
The second column in the table displays the number of “non-null” (non-empty) values in each DataFrame column. If you refer back to the first five rows of the DataFrame, you’ll notice that “NaN” appears quite frequently. “NaN” stands for “Not a Number” and is a special value used to represent missing, undefined, or unrepresentable numerical data.
When preparing datasets, like the one from MoMA, it’s crucial for people working at GLAM (Galleries, Libraries, Archives, Museums) institutions not to leave any cells empty. If left blank, users may mistakenly believe that the value was simply forgotten. By using “NaN”, the data preparers are indicating that they have no information about a particular data point. For example, when “NaN” appears under the “Circumference” column of an artwork, it means there is no available measurement for the artwork’s circumference.
Some providers of DataSets use other values instead of “NaN” to imply a missing value, such as:
| Situation | Missing Value |
|---|---|
| Numeric data | NaN or None |
| Text data | None or “Unknown” |
| Database tables | NULL |
| External systems (e.g. Excel) | “N/A”, #N/A, blank |
Returning to the DataFrame info, “non-null” values refer to values that are not NaN, NULL, N/A, or their equivalents. In other words, these are the useful values that contain meaningful information.
-
The third column in the info table shows the data type of the values in each column. A data type tells Python (or, in this case, pandas) what kind of value something is, so it knows how to handle it. In this dataset, we have three main data types: “object”, “int64”, and “float64”.
- “int” stands for integer — whole numbers without decimals (e.g., 1, 2, 3, …). The “64” in “int64” refers to the number of bits used to store the integer in memory: 64 bits. Larger sizes allow for the storage of larger numbers more accurately.
- “float” stands for floating-point numbers (or decimal numbers), such as 1.345, 12.34878, or -0.1. Similarly, “64” in “float64” indicates the size of the number in memory, using 64 bits to store each decimal.
-
Finally, in
pandas, anything that isn’t clearly a number is categorized as an “object”. Examples of objects in pandas include:- Strings (text): “apple”, “John”, “abc123”
- Lists with mixed values: [“hello”, 3, None]
- Python objects
The .info() method has already provided us with valuable
insights into the data types in moma_df and how they should
be handled during analysis. It has also performed some counting for us.
Now, we can begin counting more specific elements within this DataFrame.
For example, we can identify all the artist names in the DataFrame and
determine how many works by each artist are included in MoMA’s
collection.
Challenge
How do you think we should proceed? Can you break down this task into single steps and write the pseudocode for each step?
We need to create a new DataFrame based on moma_df
regarding the task at hand. This new DataFrame should contain two
columns: the artist names and number of times each name appears in
moma_df.
The pseudocode for this task looks something like this:
- Look at the column "Artist" in moma_df and find individual artist names.
- Count the number of times each individual artist name appears in moma_df.
- Store the artist names and the number of their mentions in a new DataFrame called artist_counts.Let’s translate the pseudocode into Python code:
PYTHON
artist_counts = moma_df['Artist'].value_counts().reset_index()
artist_counts.columns = ['Artist', 'Number of Works']
artist_counts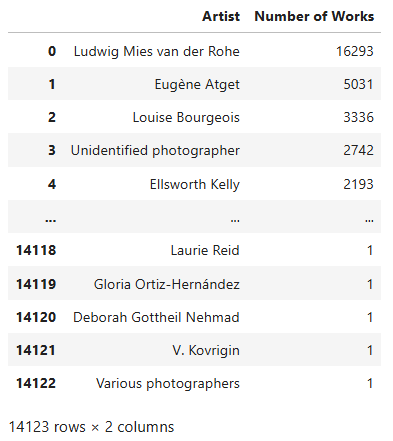
Let’s analyze the code line by line
artist_counts = moma_df['Artist'].value_counts().reset_index()When you use the .value_counts() method in
pandas, it returns a Series where:
- The index consists of the unique values from the original column in
moma_df(in this case, from the “Artist” column). - The values represent how many times each artist appears in that column.
While this format is informative, it’s not as flexible for further
analysis because it’s not a DataFrame with named columns. By adding
.reset_index(), you’re instructing pandas to convert the
index (artist names) into a regular column. Afterwards, we rename the
columns like this:
artist_counts.columns = ['Artist', 'Number of Works']Here, we’re assigning a list of two strings to rename the columns appropriately.
Now that we’ve created the artist_counts DataFrame, we
can perform statistical operations on it. While such statistical
insights may not be significant for scholarly research in art history —
since MoMA’s collection does not comprehensively represent global or
regional art histories — they do shed light on the scope and patterns of
MoMA’s collection practices.
To deepen our statistical analysis, it would be helpful to have
additional information about the artists — such as their nationality and
gender. Let’s create a new DataFrame that includes these details and
name it artist_info.
Challenge
Can you break down this task into single steps and write the pseudocode for each step?
In the new DataFrame, we need more information than just “Artist” and “Number of Works”. We also need “Gender” and “Nationality” for this task.
Here’s the pseudocode for solving this challenge:
- Extract a new DataFrame from
moma_dfthat includes only the artist names, their gender, and nationality. - Create another DataFrame from
moma_dfthat includes artist names along with the count of how many times each artist appears. - Merge these two DataFrames into a third DataFrame that combines the artist information with their work counts.
Again, let’s translate the pseudocode to Python code:
PYTHON
artist_details = moma_df.groupby('Artist')[['Gender', 'Nationality']].first().reset_index()
artist_counts = moma_df['Artist'].value_counts().reset_index()
artist_counts.columns = ['Artist', 'Number of Works']
artist_info = artist_counts.merge(artist_details, on='Artist', how='left')
artist_info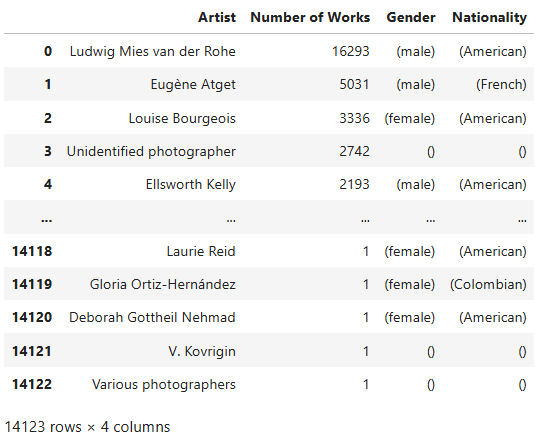
Let’s analyze the code line by line
artist_details = moma_df.groupby('Artist')[['Gender', 'Nationality']].first().reset_index()-
moma_df.groupby('Artist')groups the DataFrame by the ‘Artist’ column. Each group contains all rows associated with a single artist. -
[['Gender', 'Nationality']]selects only the ‘Gender’ and ‘Nationality’ columns from these groups, as we’re interested in these attributes. -
.first()extracts the first non-null row from each group. This is useful when an artist appears multiple times with inconsistent or missing gender/nationality data — we simply take the first available record. -
.reset_index()converts the grouped index (‘Artist’) back into a standard column, so it becomes part of the DataFrame again. - The result is saved in a new DataFrame called
artist_details, which contains one row per artist along with their gender and nationality.
artist_counts = moma_df['Artist'].value_counts().reset_index()
artist_counts.columns = ['Artist', 'Number of Works']- This code creates another DataFrame,
artist_counts, containing the number of works associated with each artist inmoma_df. - This is the same step as we took in the previous task. We use the
method
.value_counts()to count how many times each artist appears, and then use.reset_index()to turn the artist names back into a column. - The columns are renamed to ‘Artist’ and ‘Number of Works’.
artist_info = artist_counts.merge(artist_details, on='Artist', how='left')- Now we merge the two DataFrames,
artist_countsandartist_details, into one comprehensive DataFrame calledartist_info. - The
on='Artist'argument tellspandasto merge the data based on matching values in the ‘Artist’ column. -
how='left'specifies a left join: all artists fromartist_countsare kept, and any matching rows fromartist_detailsare added. If no match is found, the missing fields will be filled withNaN.
Note:
When you’re faced with complex, multi-line code and find it difficult to understand what each line - or even each function or method within a line - is doing, try the following strategy:
- Add a new cell to your Jupyter Notebook.
- Identify the specific part of the code you want to understand
better, and assign it to a variable of your choice. For example, suppose
you want to examine the DataFrame
artist_countsbefore the.reset_index()method is applied. You can assign everything before.reset_index()to a new variable — let’s call ittest_index— and then display its contents:
- Now you can compare
test_indexwithartist_counts. The differences between them will show you exactly what the.reset_index()method does.
With the artist_info DataFrame ready, we can start
exploring the composition of MoMA’s collection. Let’s begin by examining
how many works are attributed to artists of different genders. This will
give us a basic understanding of gender representation in the museum’s
holdings.
Challenge
Write the Python code that shows how many works in MoMA’s collection are attributed to artists of different genders.

It appears that MoMA holds four times as many works by male artists as by female artists, highlighting a significant gender imbalance. However, other gender-related factors should also be considered. For instance, the gender of 1,129 artists remains unspecified — possibly because the artists are unknown or the work was created by a collective.
Additionally, there are entries with gender labels such as “() (male)
(male) (male) () (male) (male) (female)”, which likely indicate that the
artwork was produced by a group of individuals with the listed genders.
To clarify this, let’s examine the moma_df dataset to
identify the artist and corresponding artwork associated with this
particular gender entry.
Challenge
Write the pseudocode to find the artist and the artwork that correspond to the gender “() (male) (male) (male) () (male) (male) (female)”.
- Define the specific gender pattern as a string.
- Filter the dataset to find all rows where the ‘Gender’ column exactly matches this pattern.
- Store the filtered rows in a new DataFrame.
Let’s translate the pseudocode into Python code:
PYTHON
gender= "() (male) (male) (male) () (male) (male) (female)"
matching_artworks = moma_df[moma_df['Gender'] == gender]
matching_artworks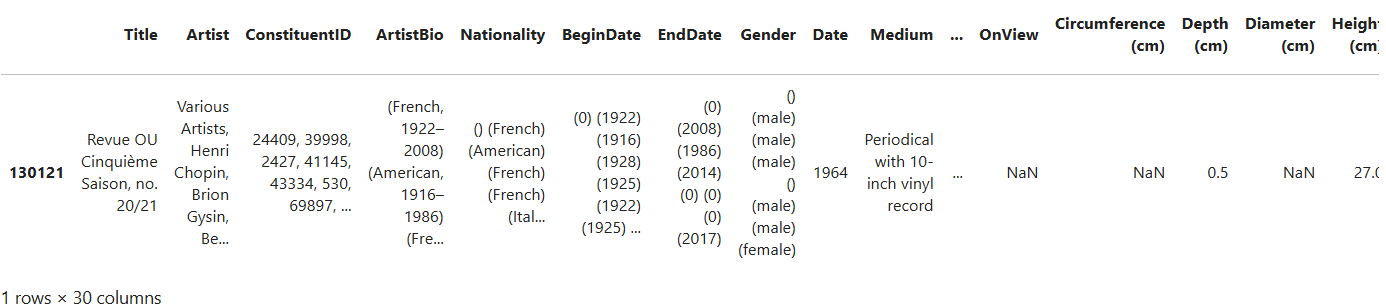
Let’s analyze the code
matching_artworks = moma_df[moma_df['Gender'] == gender]
filters the moma_df DataFrame to include only the rows
where the Gender column exactly matches the gender string defined
earlier. moma_df['Gender'] selects the Gender column from
the DataFrame, and == gender checks whether the value in
that column is exactly equal to the specified gender string.
As you can see, the artists’ name is not completely readable in the table. Let’s try to access the complete artist name for this specific artwork by adding some more pseudocode and Python code. The pseudocode for this step would look like this:
- Access the first row of the matching results.
- Retrieve the artist’s name from this row.which translates into one line of Python code:

Let’s analyze the code
Having filtered the data to include only the rows with the specified
gender, we want to work with the first one that meets the condition.
.iloc[0] in matching_artworks.iloc[0] allows
us to do this. It accesses the first row in the
matching_artworks DataFrame. .iloc[] is used
for index-based access in a DataFrame, meaning it retrieves rows based
on their position (in this case, 0 refers to the first row).
After accessing the first row using .iloc[0],
matching_artworks.iloc[0]['Artist'] selects the ‘Artist’
column from that row. This line extracts the artist’s name from the
first row that matches the gender pattern, identifying the artist who
created the artwork with the specified gender description.
Challenge
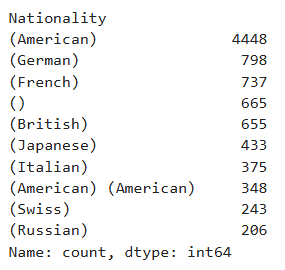
Now Let’s examine which artist nationalities are most represented in
artist_info. Write a Python code that outputs the top 10
artist nationalities from the dataset.
Challenge
Now write a code that outputs the ten least represented artist
nationalities in artist_info.

Discussion
Discuss the results with your peers in a group:
- Reflect on the insights you’ve gained through your analysis of gender, nationality, and other metadata of artworks in MoMA’s collection.
- Consider how the processes of searching and counting contributed to these insights.
- How would you interpret the numbers and other information you’ve extracted from the dataset? What do they reveal about the nature and composition of MoMA’s collection?
- Finally, think about whether this information could serve as a foundation for scientific or critical research.
Don’t stop here. To practice further, explore other features from
moma_df. Ask your own questions about these features and
apply the Python functions and methods you’ve learned so far to
investigate them and observe the results.
If you’re interested in boosting your skills in pandas,
there are lots of free tutorials on the internet that you can use. For
example, you can watch this video
tutorial on YouTube and code along with it to learn more about
useful pandas functions, methods and attributes.
Up to this point, we’ve only been conducting exploratory data analysis (EDA). This type of analysis is meant to help you become more familiar with the dataset. EDA gains scientific value only when it’s used to support a well-defined scientific argument.
Step 4 - Visualizing
Visualizing data is a key part of conducting quantitative analysis. Different visualization methods serve different analytic purposes, such as:
- Exploring relationships between features in the dataset
- Comparing trends and measurements
- Examining distributions
- Identifying patterns
- Drawing comparisons across categories or time
- Understanding statistical inference
- Enhancing data storytelling
among others. To dive deeper into data visualization for statistical inference and storytelling, see this Carpentries lesson.
Reverse engineering the code
To learn how to code effectively, it helps to approach the process from two directions at once:
- Build your skills step by step, starting from the basics—as we’ve been doing so far in this episode.
- Learn to reverse-engineer code written by others, even if it’s more advanced than your current evel.
Reverse-engineering means trying to decipher and understand someone else’s code, using it as a learning tool. Although this can be challenging, it’s one of the fastest ways to improve.
In this section, we’re going to examine two pieces of code that generate graphs using the MoMA dataset. Our goal is to understand how they work so that we can adapt similar techniques in our own projects later.
Let’s do two data visualization exercises using moma_df.
But before we create the visualizations, it’s essential to define why
we’re making them, because the purpose of a visualization guides how we
build it.
We’re going to focus on two specific goals:
- Visualize the distribution of artistic media over time in MoMA’s collection
- Compare the number of artworks in the collection by country and epoch
There are many chart types suited to different kinds of data and
questions. Likewise, Python has several powerful libraries for
visualizing data. For this exercise, we’ll use
plotly.express, a submodule of the broader
plotly library. Think of plotly as the full
toolbox, and plotly.express as the quick-access drawer with
the most commonly used tools. It’s especially great if you’re new to
coding or just want to get nice results with less code.
The pseudocode for both visualization code snippets that we are going to write looks like this:
- import the necessary libraries.
- create a new DataFrame based on `moma_df` that contains the features that we want to
analyze and/or visualize.
- choose a propor graph type from `plotly.express` that best demonstrates the features
we want to analyze.
- visualize the graph using the created DataFrame.Let’s first import the libraries we need:
Now, let’s visualize the distribution of artistic media over time in MoMA’s collection. To do so, we’re going to create a histogram.
A histogram is a type of chart that shows how often different ranges of values appear in a dataset. It groups the data into “bins” (intervals), and for each bin, it shows how many data points fall into that range using bars.
For example, if you’re analyzing ages in a list, a histogram can show how many people are in their 20s, 30s, 40s, etc.
Histograms are especially useful for:
- Understanding the distribution of your data (e.g., is it spread out, concentrated in one area, or skewed to one side?)
- Detecting outliers (values that are very different from the rest)
- Checking if your data is normal, uniform, or has some other pattern
To keep the graph clear and easy to read, we’ll focus only on the top
eight most common artistic media found in moma_df.
PYTHON
df = moma_df.copy()
df['Date'] = pd.to_numeric(df['Date'], errors='coerce')
top_media = df['Medium'].value_counts().nlargest(8).index
medium_df = df[df['Medium'].isin(top_media)]
fig = px.histogram(medium_df, x='Date', color='Medium',
nbins=50,
title='Trends in Medium Usage Over Time: the Top 8 Media')
fig.update_xaxes(title_text='Year')
fig.update_yaxes(title_text='Number of Artworks')
fig.show()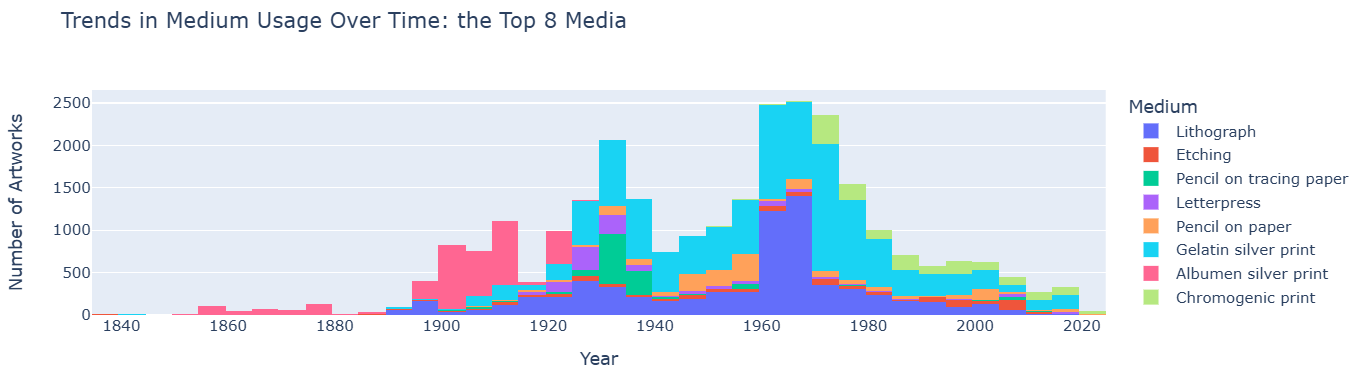
Challenge
By now, you should have gained a basic understanding of the logic behind Python syntax. In your group, discuss how the above code works and what each function, method, and argument does. Play with the arguments, change them, and see what happens.
Keep in mind that all Python libraries, along with their functions and methods, are well-documented. You can read these documentations to understand other people’s code or learn how to implement new libraries in your own code.
To understand how the histogram function from the
plotly.express module works, check out the documentation of
plotly.express.histogram here.
Here’s a line-by-line explanation of the above code:
df = moma_df.copy()- Creates a copy of the DataFrame
moma_dfand assigns it todf. This is often done to preserve the original DataFrame in case you want to modify it without affecting the source. Here, because we are going to manipulate some values inmoma_df, changing their data types and removing rows that contain empty values, we create a copy of it to keep the original DataFrame unchanged.
df['Date'] = pd.to_numeric(df['Date'], errors='coerce')- The dates in the “Date” column are objects. This line of code converts the values in the ‘Date’ column to numeric format.
- Any values that can’t be converted (like strings or invalid dates)
are set to NaN (missing values) by
errors='coerce'.
df['Date'] = pd.to_numeric(moma_df['Date'], errors='coerce')- If you remember, the dates in the ‘Date’ column were objects as
moma_df.info()showed. This line of code converts the values in the ‘Date’ column to numeric format. - Any values that can’t be converted (like strings or invalid dates)
are set to NaN (missing values) by
errors='coerce'.
top_media = df['Medium'].value_counts().nlargest(8).index-
df['Medium']selects the “Medium” column from the DataFramedf, which contains the artistic media for each artwork. -
.value_counts()counts the number of occurrences of each unique value in the “Medium” column (i.e., how many artworks belong to each medium). -
.nlargest(8)selects the top 8 most frequent media types based on their counts. -
.indexextracts the index (the actual medium types) from the result ofnlargest, which gives us the top 8 artistic media.
medium_df = df[moma_df['Medium'].isin(top_media)]-
df['Medium'].isin(top_media)checks which rows in the “Medium” column ofmoma_dfcontain one of the top 8 media from thetop_medialist. - The result is stored in a new DataFrame called
medium_df, which contains only the artworks with the top 8 most frequent media.
fig = px.histogram(medium_df, x='Date', color='Medium', nbins=50, title='Trends in Medium
Usage Over Time', labels={'Date': 'Year', 'count': 'Number of Artworks'})The px.histogram() function from
plotly.express creates a histogram. It takes the following
arguments:
-
medium_df: The data to visualize (i.e., the filtered DataFrame with the top 8 media) -
x='Date': The variable to be plotted on the x-axis, which is the “Date” column. This represents the year each artwork was created. -
color='Medium': This argument colors the bars by the “Medium” column, so you can distinguish between the different artistic media. - When you set the X-axis to the
Datecolumn inmedium_dfand the bar colors to the top 8 media,Plotly Expressautomatically counts the occurrences of each artistic medium and plots them on the Y-axis. Therefore, it is not necessary to explicitly specify the column frommedium_dfthat should be plotted on the Y-axis. -
nbins=50: Specifies the number of bins for the histogram (i.e., how the years will be grouped). -
title='Trends in Medium Usage Over Time': The title of the plot.
fig.update_xaxes(title_text='Year')
fig.update_yaxes(title_text='Number of Artworks')These lines set the title of the X-axis to “Year” and the title of the Y-axia to “Number of Artworks.”
fig.show()- This line displays the plot created by
plotly.express. It renders the histogram in an interactive format, allowing you to hover over the bars to view detailed information.
Try reading and interpreting the graph. Explain what it shows in simple, natural language. Based on the graph, draw a conclusion about MoMA’s collection.
Challenge
Now, let’s visualize a second graph using the MoMA database. This time, the process will be a bit more complex. It’s up to you to understand the functionality of the code and what information the resulting graph represents.
PYTHON
df = moma_df.copy()
df['Date'] = pd.to_numeric(df['Date'], errors='coerce')
df = df.dropna(subset=['Date', 'Nationality'])
grouped = df.groupby(['Date', 'Nationality']).size().reset_index(name='Count')
top_nationalities = df['Nationality'].value_counts().nlargest(7).index
grouped = grouped[grouped['Nationality'].isin(top_nationalities)]
fig = px.scatter(grouped, x='Date', y='Nationality', size='Count', color='Nationality',
title='Frequency of Artworks by Nationality Over Time')
fig.update_xaxes(title_text='Year')
fig.update_yaxes(title_text='Nationality')
fig.show()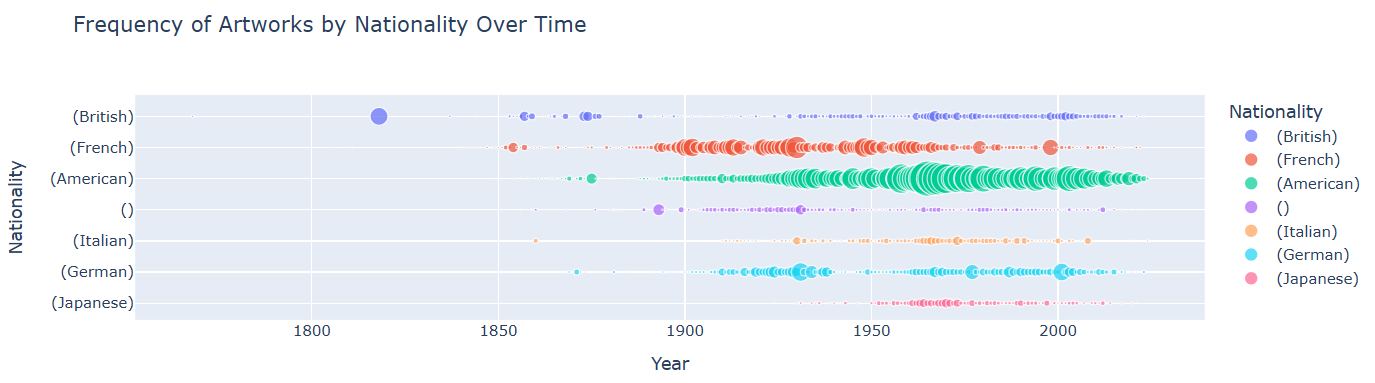
df = df.dropna(subset=['Date', 'Nationality'])- Removes rows from
dfwhere either ‘Date’ or ‘Nationality’ is missing (NaN). - Ensures that the data used for analysis is clean and has valid date and nationality info.
grouped = df.groupby(['Date', 'Nationality']).size().reset_index(name='Count')- This line should already be familiar to you. It groups the cleaned DataFrame by ‘Date’ and ‘Nationality’.
-
.size()counts how many entries fall into each group. -
.reset_index(name='Count')turns the grouped result into a new DataFrame with columns: ‘Date’, ‘Nationality’, and ‘Count’.
top_nationalities = df['Nationality'].value_counts().nlargest(7).index- Finds the 7 most common nationalities in the dataset by counting occurrences in the ‘Nationality’ column.
- Returns the index (i.e. the nationality names) of the top 7.
grouped = grouped[grouped['Nationality'].isin(top_nationalities)]- Filters the
groupedDataFrame to only include rows where the ‘Nationality’ is one of the top 7 most frequent ones. - Helps focus the plot on the most represented nationalities.
fig = px.scatter(grouped, x='Date', y='Nationality', size='Count', color='Nationality',
title='Frequency of Artworks by Nationality Over Time',
labels={'Date': 'Year'})
fig.show()- Uses
plotly.express(px) to create a scatter plot.-
x='Date': places dates on the x-axis. -
y='Nationality': places nationalities on the y-axis. -
size='Count': size of the points represents how many artworks fall into each (date, nationality) combo. -
color='Nationality': assigns different colors to different nationalities.
-
-
title: sets the chart title. -
labels={'Date': 'Year'}: renames the x-axis label. -
fig.show(): displays the interactive plot.
A scatter plot is a type of chart that shows the relationship between two numerical variables. Each point on the plot represents one observation in the dataset, with its position determined by two values — one on the x-axis and one on the y-axis.
Scatter plots are useful for:
- Checking if there’s a relationship or pattern between two variables
- Seeing how closely the variables are related (positively, negatively, or not at all)
- Detecting outliers or unusual data points
The Data Visualization Workflow:
By now, you should have developed a basic understanding of the data visualization workflow. You can infer this from the two visualization exercises we completed above. When visualizing data, we generally follow these steps:
Identify the features of the dataset we want to analyze and the relationships between them that are of interest to us.
Choose the appropriate graph type based on the goal of our analysis, and decide which Python library we will use to create it (e.g., Matplotlib, Seaborn, Plotly).
Extract the relevant data - the specific values and features we plan to visualize - from the original dataset, and store it in a separate variable for clarity and ease of use.
-
Create the graph. Graphs in Python offer many customizable elements, and we can map different dataset features to these graphical properties. In the case of histograms and scatter plots (which we’ve used here), common properties include:
- The values along the X and Y axes
- The size of the bars (in histograms) or dots (in scatter plots)
- The color of the bars or dots
- Formulate appropriate research questions when working with tabular data.
- Identify the quantitative analysis methods best suited to answering these questions.
- Break down the analysis into smaller tasks, translate them into computer logic using pseudocode, and implement them in Python code.
- Learn about Python functions and methods.
- Learn about histograms.
- Use
pandasfor counting and searching values in tabular datasets. - Use
plotly.expressfor visualizing tabular data.
Content from Analyzing Text Data
Last updated on 2026-03-02 | Edit this page
Estimated time: 183 minutes
Overview
Questions
- What quantitative analysis operations can be performed on data composed of literary texts?
- How can these operations be translated into Python code?
Objectives
- Learn how to perform word frequency analysis on literary texts.
- Learn how to visualize a word cloud from a text.
- Learn how to perform keyword-in-context analysis on literary texts.
In the previous episode, we worked with tabular data and performed three core operations often used in quantitative humanities research: counting, searching, and visualizing. In this episode, we’ll apply similar operations to text data. We’ll focus on analyzing the full texts of plays written by two prominent English playwrights from the 16th century: William Shakespeare (1564–1616) and Christopher Marlowe (1564–1593). We’ll learn how to perform the following types of analysis on these texts using Python:
- Word frequency analysis
- Creating a word cloud
- Keyword-in-context (KWIC) analysis
Because text fundamentally differs from tabular data, we’ll take a completely different approach in this episode compared to the previous one, using distinct Python libraries and syntax to carry out analytical tasks.
To save the data locally on your computer, go ahead and run the
following Python code. It creates a directory named data in
the same path where your Jupyter Notebook is located, if the directory
doesn’t exist already. Then, it downloads the directories
shakespeare and marlowe and their contents
from GitHub and saves them in data.
PYTHON
import os
import requests
# Base URLs for each directory
base_urls = {
"shakespeare": "https://raw.githubusercontent.com/HERMES-DKZ/python_101_humanities/main/episodes/data/shakespeare",
"marlowe": "https://raw.githubusercontent.com/HERMES-DKZ/python_101_humanities/main/episodes/data/marlowe"
}
# Files to download
file_lists = {
"shakespeare": ['alls_well_ends_well.txt', 'comedy_of_errors.txt', 'hamlet.txt', 'julius_caesar.txt',
'king_lear.txt', 'macbeth.txt', 'othello.txt', 'romeo_and_juliet.txt', 'winters_tale.txt'],
"marlowe": ['doctor_faustus.txt', 'edward_the_second.txt', 'jew_of_malta.txt', 'massacre_at_paris.txt']
}
# Create 'data' folder and subfolders
os.makedirs("data/shakespeare", exist_ok=True)
os.makedirs("data/marlowe", exist_ok=True)
# Download each file
for author, files in file_lists.items():
for file_name in files:
url = f"{base_urls[author]}/{file_name}"
local_path = f"data/{author}/{file_name}"
response = requests.get(url)
if response.status_code == 200:
with open(local_path, "w", encoding="utf-8") as f:
f.write(response.text)
print(f"Downloaded: {local_path}")
else:
print(f"Failed to download {url} (status code: {response.status_code})")For now, it’s not necessary to go into details about how the above code functions. You’ll learn more about web scraping in later episodes.
In Jupyter Notebook, save the path to each directory in a variable like this:
When working with text data, it’s essential to clean the text before beginning the analysis. During this cleaning process, you will remove characters that indicate line breaks and other unwanted symbols that might affect your analysis. I’ve performed some minimal cleaning on the text data we will be using in this episode.
Unfortunately, we won’t be able to cover text cleaning in detail in this lesson. However, you’ll find a wealth of helpful video tutorials online that can guide you through the process of cleaning text data on your own.
1. Word Frequency Analysis
Word frequency analysis is a foundational method in computational literary studies that involves counting how often individual words appear in a text or a collection of texts. By quantifying language in this way, scholars can identify patterns, emphases, and stylistic tendencies within texts.
Word frequency analysis can serve several purposes in literary research:
- It can reveal recurring themes or motifs by highlighting which words are most frequently used, offering insight into a text’s dominant concerns or rhetorical strategies.
- It can also be used to compare the linguistic style of different authors, genres, or historical periods, helping to map changes in diction, tone, or subject matter over time.
- In studies of individual works, frequency analysis can assist in tracking narrative focus or character development by examining how often certain names, places, or concepts appear across a text.
- Beyond individual texts, word frequency analysis can also support authorship attribution, genre classification, and the study of intertextuality.
We’ll explore which words were most frequently used in nine of Shakespeare’s plays and four of Marlowe’s, all included in our dataset. This analysis will help us gain insight into the themes and rhetoric of some of the most influential English plays written in 16th-century England.
Step 1: Loading the Dataset into the Script
Unlike the previous episode, where the dataset was stored in a single
.csv file, the dataset for this episode is stored in
thirteen separate .txt files. To store multiple texts in a
single Python variable, we can construct a Python
dictionary.
Python dictionaries are enclosed in curly brackets: { }. A Python dictionary is a built-in data structure used to store pairs of related information. One part of the pair is called the key, and the other part is the value. Each key is linked to a specific value, and you can use the key to quickly access the value associated with it. A Python dictionary is structured exactly like a linguistic dictionary: just as you look up a word in a linguistic dictionary to find its definition, you can store values under keys in a Python dictionary to be able to use the keys to retrieve the values later.
Here’s how you might define a Python dictionary:
PYTHON
my_vacation_plan= {
'budget': 100,
'destination': 'Johannesburg',
'accomodation': 'Sunset Hotel',
'activities': ['hiking', 'swimming', 'biking'],
'travel by plane': TRUE
}In a Python dictionary, both keys and values can be a variety of data types, but with some important rules:
Keys:
There are two main things to know about keys:
- They must be unique: You can’t have two identical keys in the same dictionary.
- They must be immutable: This means they have to be data types that cannot change.
Valid key types include:
- Strings (e.g., ‘budget’)
- Numbers (e.g., 1, 3.14)
- Tuples (e.g., (1, 2)), as long as the tuple itself doesn’t contain mutable objects
You cannot use lists, dictionaries, or other mutable types as keys.
We’re going to create two dictionaries: one for Marlowe’s plays, and
one for Shakespeare’s. The keys in each dictionary will be the names of
the .txt files — which correspond to the play titles — and
the values will be the full texts of the plays. First, let’s build a
list of keys for each dictionary:
PYTHON
import os
shakespeare_files = [f for f in os.listdir(shakespeare_path)]
marlowe_files = [f for f in os.listdir(marlowe_path)]
print("File names corresponding to Shakespeare:")
for file in shakespeare_files:
print ("*", file)
print()
print("File names corresponding to Marlowe:")
for file in marlowe_files:
print ("*", file)
Let’s analyze the code line by line
In the above code, we’re defining two lists:
shakespeare_files and marlowe_files.
A list in Python is a type of data structure used to store multiple items in a single variable. Lists can hold different types of data like numbers, strings, or even other lists. Items in a list are ordered, changeable (mutable), and allow duplicate values- meaning that the same value can appear multiple times in the list without any issue.
Python lists are enclosed in square brackets: [ ]. A Python list could look like this:
import osThis line imports Python’s built-in os module, which
provides functions for interacting with the operating system. This
includes functions to work with files and directories.
shakespeare_files = [f for f in os.listdir(shakespeare_path)]
marlowe_files = [f for f in os.listdir(marlowe_path)]This is a list comprehension, which is a short way to create a new
list using a for loop.
A for loop is used in Python to repeat an action for every item in a group (like a list). You can think of it as a way to go through a collection of things one by one and do something with each item. Here’s a basic idea:
for item in group:
do something with itemThe loop takes one item from the group, does something with it, then moves on to the next, until there are no more items left.
os.listdir(shakespeare_path)calls a function namedlistdir()from theosmodule. It takes the path to a directory (given inshakespeare_path) and returns a list of all the names of files and folders inside that directory.for f in os.listdir(shakespeare_path)is aforloop. It goes through each item in the list returned byos.listdir(shakespeare_path). For each item (each filename), it temporarily gives it the namef. So,fis a variable that holds each filename one by one.The list comprehension
[f for f in os.listdir(shakespeare_path)]basically says: “Take eachf(each filename) from the directory, and put it into a new list.” That new list is then assigned to the variableshakespeare_files.
marlowe_files is another list that is created through
the exact same process.
print("File names corresponding to Shakespeare:")
for file in shakespeare_files:
print ("*", file)
print()
print("File names corresponding to Marlowe:")
for file in marlowe_files:
print ("*", file)Having created these lists, we proceed to print their items one by
one, again using a for loop. Notice how the
for loop is being implemented here as compared to the list
comprehension above. Can you see the logic behind its syntax?
In order to use the file names as dictionary keys, we need to get rid
of their .txt extension. To do so, let’s write a function
that does exactly this for us. The function takes a list of file names,
removes their .txt extensions, and returns a list of file
names without extension:
PYTHON
def extention_remover (file_names):
filenames_without_extention = [file.removesuffix(".txt") for file in file_names]
return filenames_without_extentionNow let’s apply the function to shakespeare_files and
marlowe_files and store the results in two new lists,
shakespeare_works and marlowe_works. We’ll
print the resulting lists to make sure that the file extensions have
been successfully removed from them:
PYTHON
shakespeare_works= extention_remover(shakespeare_files)
marlowe_works= extention_remover(marlowe_files)
print (shakespeare_works)
print (marlowe_works)
So far, so good! Now we can create dictionaries containing all the
works by each author. To do this, we’ll define a function that handles
it for us. We’ll also incorporate the earlier steps - specifically,
reading file names from a directory and applying the
extension_remover function to strip their extensions. This
way, the new function can take the path to a folder containing our
literary works and return a dictionary where each file name (without the
extension) becomes a key, and the corresponding literary text becomes
the value:
PYTHON
def literary_work_loader (path):
def extention_remover (file_names):
filenames_without_extention = [file.removesuffix(".txt") for file in file_names]
return filenames_without_extention
file_names= [f for f in os.listdir(path)]
work_names= extention_remover (file_names)
full_text_dict= {}
for file, work in zip(file_names, work_names):
with open(f"{path}/{file}", "r", encoding="utf-8") as f:
full_text = f.read().replace("\n", "")
full_text_dict[work]= full_text
return full_text_dictLet’s analyze the code line by line
The first few lines of the above code are already familiar to you. So let’s only focus on the part where we are creating a dictionary:
full_text_dict= {}In this line, we are creating an empty dictionary and assigning it to
a variable named full_text_dict.
for file, work in zip(file_names, work_names):This line sets up a for loop. It lets us go through two
lists — file_names and work_names — at
the same time. The zip() function pairs up each
file name (with the .txt extension) and its matching
cleaned-up name (with no .txt extension). So for each step
in the loop:
-
filewill be the full file name (like “hamlet.txt”), and -
workwill be the name without the.txtpart (like “hamlet”).
with open(f"{path}/{file}", "r", encoding="utf-8") as f:This line opens a file so that we can read its contents.
-
f"{path}/{file}"is an f-string that builds the complete path to the file.
An f-string (short for formatted string) is a way to create strings that include variables inside them. It makes it easier to combine text and values without having to use complicated syntax. Here’s the basic idea:
name = "Bani"
greeting = f"Hello, {name}!"
print(greeting)Output: Hello, Bani!
The f before the opening quotation mark tells Python:
This is a formatted string. Inside the string, you can use curly braces
{ } to include variables (like name) or even expressions
(like 1 + 2).
If path equals “./data/shakespeare” and
file equals “hamlet.txt”, this becomes
“./data/shakespeare/hamlet.txt”.
-
"r"means we are opening the file in read mode (we are not changing it). -
encoding="utf-8"makes sure we can read special characters (like letters with accents). -
as fgives the file a nickname:f, so we can use it in the next line. - The
withkeyword automatically closes the file when we’re done reading it, which is a good habit.
full_text = f.read().replace("\n", "")-
f.read()reads the entire content of the file and stores it in a variable calledfull_text. -
.replace("\n", "")removes all the newline characters (\n) from the text by replacing them with a string with zero length, containing no characters (““). Normally, text files have line breaks. This line of code removes the line breaks and puts everything together in one big line of text.
full_text_dict[work] = full_textThis line adds a new entry to the full_text_dict
dictionary.
-
workis used as the key — that’s the cleaned-up name like “hamlet”. -
full_textis used as the value — that’s the complete content of the filehamlet.txt.
return full_text_dictThis line returns the dictionary we built. Whoever uses this function
will get back a dictionary with all the file names (without
.txt) as keys and their full texts as values.
Now that we have the function, we can use it to create two dictionaries containing the works of Shakespeare and Marlowe:
PYTHON
shakespeare_texts= literary_work_loader (shakespeare_path)
marlowe_texts= literary_work_loader (marlowe_path)Try printing the marlowe_texts dictionary, which is
shorter, to get an overview of its structure and content.
Step 2: Performing Word Frequency Analysis using spaCy
Performing word frequency analysis is faster and easier than you
think. This has become possible thanks to pretrained machine
learning models that the Python library spaCy
offers.
A pretrained machine learning model is a model that has already been trained on a large dataset by other developers. Instead of starting from scratch, you can use this model to perform tasks like image recognition, language processing, or object detection. It has already learned patterns and features from the data, so you don’t need to teach it everything again. This saves time, computing resources, and often improves accuracy, especially when you don’t have a lot of your own data to train a model from the beginning. You can also fine-tune it to work better on your specific task by giving it a smaller set of relevant data.
We are going to use spaCy’s en_core_web_md
model for this exercise. You can directly download the model from your
Jupyter Notebook by running the following code:
Once you have downloaded the en_core_web_md model, it remains on your computer, ensuring you don’t need to download it again the next time you run the following lines of code in Jupyter Notebook.
Now, we will write a function that takes the full text of each play, tokenizes it, and counts the number of times each word appears in that text.
Tokenizing a text means breaking a piece of text into smaller parts — usually words, subwords, or sentences — so that a computer can work with it more easily.
In natural language processing (NLP), tokenization is often the first step when preparing text for most analysis tasks like word frequency analysis, language modeling, translation, or sentiment analysis.
The following example demonstrates how a sentence can be tokenized:
text = "I love Python programming."
tokens = ['I', 'love', 'Python', 'programming']In this case, each word is a token. However, more advanced tokenizers (like those in NLTK, spaCy, or transformers) can handle punctuation, subwords, and special characters more intelligently.
Tokenization is important in NLP because computers don’t understand raw text.
PYTHON
import spacy
from collections import Counter
def token_count(text):
nlp = spacy.load("en_core_web_md")
doc = nlp(text)
words = [
token.lemma_.lower()
for token in doc
if token.is_alpha # Keep alphabetic tokens only
and not token.is_stop # Exclude stop words
and token.pos_ != "VERB" # Exclude verbs
]
return Counter(words)Challenge
Work with a partner and try to interpret the code above. Answer the following questions:
- What do the imported libraries do?
- What does the function do?
- Can you recognize the list comprehension in the function? How is is structured?
- What Python object does the function return? What shape could it possibly have?
Let’s analyze the code line by line and answer the above questions:
spacyis a library that helps Python understand and work with natural language or human language (text). It can tokenize text, recognize parts of speech (like nouns or verbs), and more.Counteris a class from thecollectionsmodule. It creates special dictionary-like objects that automatically count how often each item appears in an iterable, such as a list.The function
token_countprocesses a string of text and returns a count of specific words, excluding common words and verbs. Let’s break down what happens in the function step by step:
nlp = spacy.load("en_core_web_md")This line loads en_core_web_md, the pre-trained machine
learning model from spaCy that we have already downloaded,
and assigns it to the variable nlp. This model has been
trained on a large collection of English text and it can recognize
words, their part of speech (like nouns or verbs), their base forms
(lemmas), and more. We are assigning the loaded model
doc = nlp(text)Here, we use nlp to tokenize the text that is given to
the token_count function as an argument. The result is a
Doc object, stored in the variable doc. The
Doc object represents the entire text and contains a
sequence of Token objects. Each token is a word, punctuation mark, or
other meaningful unit that the model has identified.
From there, the function filters and counts certain words from
doc. We define which words these should be in the following
list comprehension.
words = [
token.lemma_.lower()
for token in doc
if token.is_alpha
and not token.is_stop
and token.pos_ != "VERB"
]This list comprehension has the following structure:
[token.lemma_.lower() for token in doc if ...]It means:
- Go through each word (
token) in the text (doc), - Convert it to its lemma (basic form, like “run” instead of “running”),
- Make it lowercase,
- But only include it if it’s a word (no punctuation), not a stop word, and not a verb.
Stop words are very common words in a language — like “the”, “and”, “is”, “in”, or “of”. These words are important for grammar, but they usually don’t carry much meaning on their own. In natural language processing, we often remove stop words because:
- They appear very frequently, so they dominate word counts.
- They don’t help us understand what the text is about.
- They’re similar across texts, so they’re not useful for comparing different documents.
We are also excluding verbs because, in performing this concrete word frequency analysis on the text of Marlowe and Shakespeare, we are more interested in nouns and adjectives, not in verbs.
The function returns a Counter object. This is like a
dictionary where:
- Each key is a word,
- Each value is the number of times that word appeared.
So the shape is something like:
{'word1': 3, 'word2': 1, 'word3': 2}We are now just one step away from obtaining the word frequencies in
the entire text collections by Marlowe and Shakespeare. While the
token_count function only counts words in a single text
file, we have dictionaries that contain multiple text files: four texts
by Marlowe and nine by Shakespeare.
Therefore, we need an additional function that takes a dictionary — not just a single text file — and counts the words in all the texts that exist as the values of keys in that dictionary. This approach allows us to count words not in a single text, but across a collection of texts written by a single author.
Writing this new function will be relatively easy, as we will
integrate the token_count function within it, which handles
most of the work for us.
PYTHON
def token_frequency_count (text_dict):
def token_count(text):
nlp = spacy.load("en_core_web_md")
doc = nlp(text)
words = [
token.lemma_.lower()
for token in doc
if token.is_alpha
and not token.is_stop
and token.pos_ != "VERB"
]
return Counter(words)
total_counts = Counter()
for key, value in text_dict.items():
total_counts += token_count (value)
return total_countsLet’s analyze the code’s last lines
The token_frequency_count function contains the
token_count function that we have written previously. After
defining the token_count function, we are creating
an empty Counter object (which has the structure of a
Python dictionary) and assigning it to the variable
total_counts.
Then, we are iterating through the keys and values of the input
dictionary, namely text_dict, using a for loop. The for
loop does the following:
- It treats each key-value pair as an
item. - It goes to the first item using its key, and reads the value of that key, which is the full text of a play.
- It uses the
token_countfunction to create aCounterobject containing all the desired words (tokens) from that text and adds thatCounterobject tototal_counts. - Then it goes to the next
item(key-value pair) intext_dictand performs the above operations again. It keeps counting words from every text intext_dictand adding them tototal_countsuntil it reaches the lastitemintext_dict.
Let’s apply the token_frequency_count function to the
dictionaries we have created from the Marlowe and Shakespeare texts and
take a look at the frequency of words used in the texts written by
Marlowe as an example:
PYTHON
shakespeare_frequency = token_frequency_count (shakespeare_texts)
marlowe_frequency = token_frequency_count (marlowe_texts)
marlowe_frequency
The output above displays some of the most frequent words used by Christopher Marlowe in the four plays we are analyzing.
In your Jupyter Notebook, also display the frequency of words used by Shakespeare and compare both results.
As you can see, comparing the two results can be time-consuming and unintuitive, as they are not displayed next to each other in Jupyter Notebook.
Therefore, in the next step, we will visualize these word frequencies to gain a better overview of the contents of the texts written by each playwright. This will also allow us to compare their linguistic styles and literary themes.
Step 3: Visualizing Word Frequencies
We have already worked with the plotly.express module in
the previous episode, where we visualized dataframes. We will implement
the same module in this episode as well.
Let’s write a function that takes a Counter object
containing a dictionary of word frequencies (freq_dict),
the number of the most frequent words to display in the graph
(top_n), and the title of the graph (title) as
parameters. This function will create a bar chart of the frequency of
the selected words within the Counter object:
PYTHON
import plotly.express as px
import pandas as pd
def plot_frequencies (freq_dict, top_n, title):
most_common = freq_dict.most_common(top_n)
df = pd.DataFrame(most_common, columns=['word', 'frequency'])
fig = px.bar(df, x='word', y='frequency', title=title, text='frequency')
fig.show()Let’s analyze the code’s last lines
most_common = freq_dict.most_common(top_n)This line gets the top n most frequent words from
freq_dict and stores them in a list we have called
most_common. This list contains tuples that look
like this: (word, frequency). So, for example, the
value stored in most_common for the top three words that
appear in Shakespeare plays would be:
[('thou', 1136), ('shall', 759), ('thy', 725)]
A tuple in Python is a collection data type used to store multiple
items in a single variable, characterized by its immutability, meaning
that once created, its contents cannot be changed; it maintains the
order of elements, ensuring they appear in the same sequence as defined;
and it can contain heterogeneous data types, allowing for integers,
strings, and even other tuples within a single tuple. Tuples are defined
using parentheses and commas, such as in the example:
(1, "apple", 3.14, True).
df = pd.DataFrame(most_common, columns=['word', 'frequency'])This turns the most_common list into a dataframe using
pandas and stores the dataframe in a variable named
df. It gives the columns the names ‘word’ and ‘frequency’.
The dataframe format is what plotly expects when making a
chart.
fig = px.bar(df, x='word', y='frequency', title=title, text='frequency')
fig.show()The first line creates a bar chart using the express
module from the plotly library. It takes the following
arguments:
-
df: the dataframe created in the previous line -
x='word': words go on the x-axis -
y='frequency': their counts go on the y-axis -
title=title: the chart gets the title that is passed to the function. -
text='frequency': shows word frequencies above the bars for clarity
Finally, fig.show() displays the chart in Jupyter
Notebook.
Now that we have the function, let’s pass the necessary arguments to it and visualize two bar charts displaying the 20 most frequent words that appear in the Marlowe and Shakespeare plays:
PYTHON
plot_frequencies(shakespeare_frequency, 20, "Top 20 Words in Shakespeare's Works")
plot_frequencies(marlowe_frequency, 20, "Top 20 Words in Marlowe's Works")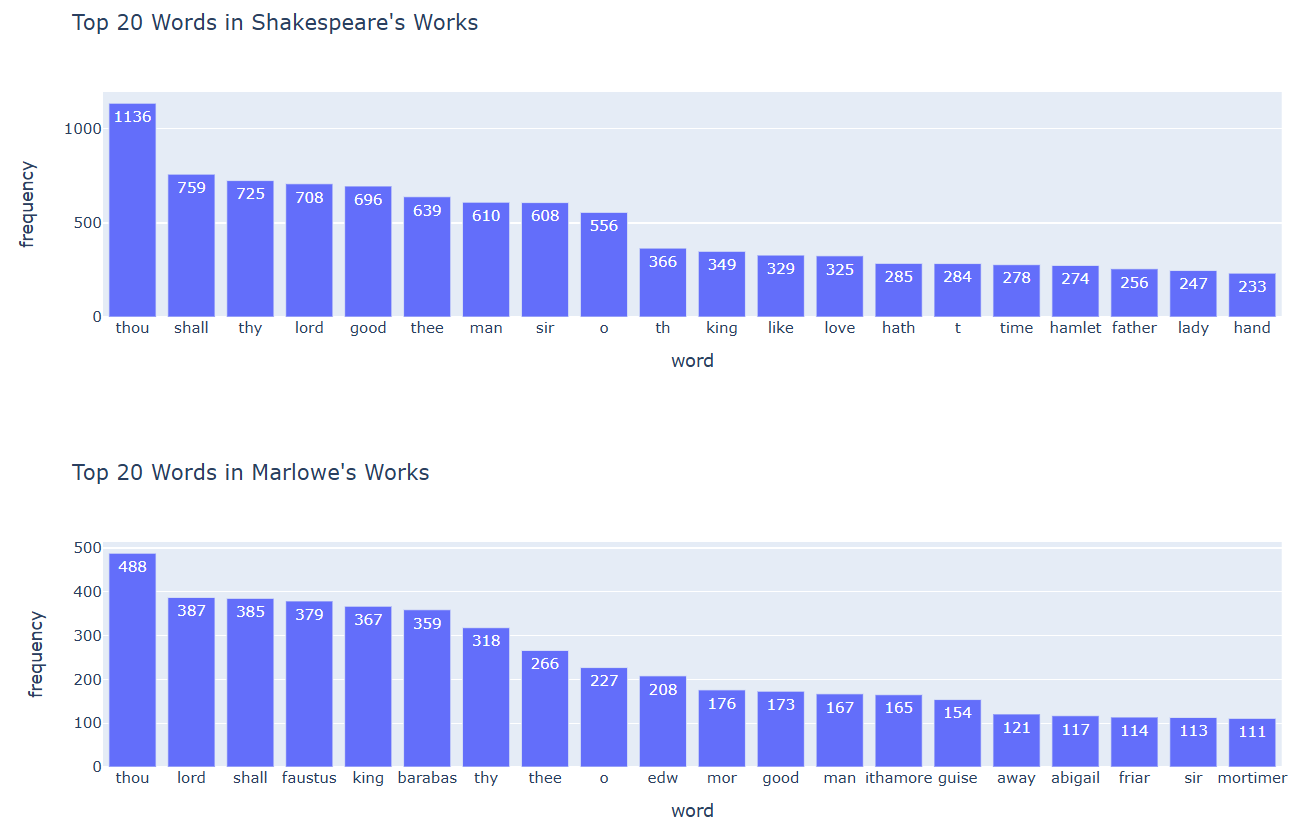
In a group, interpret the bar charts you have just visualized:
What information do these word frequencies reveal about the content and style of the plays written by the two selected playwrights?
Are there any common words among the 20 most frequent words from the works of each playwright? What do these commonalities indicate about the style of English playwrights from the 16th century?
Do you think this observation can be generalized to all 16th-century authors from England? Why or why not?
2. Creating a Word Cloud
Another way to visualize the most frequent words in a text is by creating a word cloud. Word clouds are visual representations of text data where the size of each word indicates its frequency.
There is a specific Python library named WordCloud that
does exactly this for you. To visualize a word cloud, we will use single
texts rather than the entire text collection by each author. Let’s write
code that visualizes a word cloud for Shakespeare’s early play, “Comedy
of Errors”:
PYTHON
import matplotlib.pyplot as plt
from wordcloud import WordCloud
text = shakespeare_texts['comedy_of_errors']
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
Let’s analyze the code line by line
In this analysis, only lines of code are included that may be new to you.
from wordcloud import WordCloudHere, we are importing the WordCloud class from the
wordcloud library. This library is specifically designed to
create word clouds.
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text)In this line, we create an instance of the WordCloud
class with specific parameters:
-
width=800: Sets the width of the word cloud image to 800 pixels. -
height=400: Sets the height of the word cloud image to 400 pixels. -
background_color='white': Sets the background color of the word cloud to white.
The .generate(text) method takes the text
variable (which contains the Shakespeare play) and generates the word
cloud based on the frequency of words in that text. The result is stored
in the variable wordcloud.
plt.figure(figsize=(10, 5))This line creates a new figure for plotting with a specified size.
The figsize parameter sets the dimensions of the figure to
10 inches wide and 5 inches tall.
plt.imshow(wordcloud, interpolation='bilinear')Here, we use the imshow function to display the
generated word cloud image. The interpolation='bilinear'
argument is used to improve the appearance of the image by smoothing it,
which can make it look better when resized.
plt.axis('off')This line turns off the axes of the plot. By default, plots have axes that show the scale, but for a word cloud, we typically want to hide these axes to focus on the visual representation of the words.
Reflect
Look again at the word cloud we have created. Can you identify the names of the play’s main characters?
3. Keyword-in-Context (KWIC) Analysis
In the previous section on word frequency analysis, we saw that counting the frequency of words in a body of work can provide some information on the style and themes of literary works written by certain authors or in a certain epoch.
These words and their contribution to style and meaning can be analyzed even more effectively if you look at the context they appear in. Keyword-in-context (kwic) analysis allows you to automate the search for the context in which each word appears.
In this section, I’m going to present you with a simple code that does exactly this for you:
PYTHON
import nltk
from nltk.text import Text
from nltk.tokenize import word_tokenize
nltk.download('punkt') #run this line only once and then comment it out.
def kwic_analyze (text, keyword, width=140, lines=20):
tokens = word_tokenize(text)
nltk_text = Text(tokens)
nltk_text.concordance(keyword, width=width, lines=lines)
kwic_analyze (marlowe_texts['jew_of_malta'], "lord", width=120, lines= 20)
Can you tell how the above code works?
If you have studied this Python lesson from the very beginning and mastered the concepts and methods from Episode 1 up to this point, you should be able to understand what the above code does.
Experiment with the arguments you are passing to the
kwic_analyze function and observe the output. What does
each argument do within the function?
import nltkThis imports the Natural Language Toolkit (NLTK)
library. NLTK is a popular Python library for processing
and analyzing natural language (text).
from nltk.text import TextThis imports the Text class from the
nltk.text module. The Text class provides
useful tools for analyzing text, including functions like
concordance() for keyword-in-context (KWIC) analysis.
from nltk.tokenize import word_tokenizeThis imports the word_tokenize function from
NLTK. It tokenizes a string of text by breaking it into
individual words and punctuation marks.
nltk.download('punkt')This downloads the punkt tokenizer model, which
word_tokenize depends on to split text into words. Once you
have downloaded this model, you can comment out this line of code
because you don’t need it any more.
def kwic_analyze (text, keyword, width=140, lines=20):This defines a function named kwic_analyze that takes
four parameters:
-
text: the full text you want to search -
keyword: the word you want to find in context -
width: how many characters of context to show around the keyword (default is 140) -
lines: how many keyword matches to display (default is 20)
tokens = word_tokenize(text)This breaks the input text into a list of tokens, using the
word_tokenize function.
nltk_text = Text(tokens)This creates an nltk.Text object from the list of
tokens. This object lets you use text analysis methods, such as
concordance().
nltk_text.concordance(keyword, width=width, lines=lines)This searches the text for the given keyword and displays each occurrence in context.
-
widthcontrols how much surrounding text is shown. -
lineslimits how many matches to show.
Challenge
Can you write a function that takes the dictionary containing all
works by an author — instead of taking only one text — as well as the
keyword, width of the context, and number of lines, and returns that
keyword in the context of each one of the texts within the dictionary?
You can integrate the kwic_analyze function from above into
the function that you are writing.
PYTHON
import nltk
from nltk.text import Text
from nltk.tokenize import word_tokenize
def kwic_analyze_all(texts_dict, keyword, width=140, lines=20):
def kwic_analyze(text, keyword, width=width, lines=lines):
tokens = word_tokenize(text)
nltk_text = Text(tokens)
nltk_text.concordance(keyword, width=width, lines=lines)
for title, text in texts_dict.items():
print(f"\nContext for '{keyword}' in '{title}':")
print()
kwic_analyze(text, keyword, width, lines)Reflect
Examine other plays by both authors and display the keyword “lord” in its context within these texts. Does the word, in each context, refer to “God,” or is it used to address a person of higher social rank?
Is there a relationship between these use cases and the genre and topic of the plays?
KWIC analysis allows you to see the context in which each keyword appears. It is helpful when you want to quickly examine the texts you are analyzing and the context of individual keywords without performing a close reading of the text.
If these contexts seem relevant to you as a researcher, you can consider reading the entire text to gain an even better understanding of the contexts of the keywords on which your research is focused.
- Formulate appropriate quantitative research questions when working with data composed of literary texts.
- Learn about lists, for loops, f-strings, and tuples in Python.
- Get to know and use the Python libraries spaCy, wordcloud, and NLTK.
- Perform word frequency analysis using spaCy.
- Generate word clouds using worldcloud.
- Perform keywprd-in-context analysis using NLTK.
Content from Analyzing Network Data
Last updated on 2026-03-02 | Edit this page
Estimated time: 181 minutes
Overview
Questions
- What are networks in the sense that we mean in network analysis?
- What is the structure of a network like and what kind of data can be treated as network data?
- What is the difference between network analysis and network visualization?
- When is it meaningful to perform network anaylsis and network visualization?
Objectives
- Learn the basics of network science and network analysis.
- Learn about the structure of network data.
- Learn to visualize networks.
1. Basics of Network Analysis
What are Network Science and Network Analysis?
Network Science is an interdisciplinary field that studies complex networks, which are structures comprised of interconnected nodes (or vertices) and edges (or links). These networks can represent various real-world systems such as social networks (for example on social media), transportation networks, biological networks, and more. The aim of network science is to understand the topological structure of networks and the relationships that can be discovered within them.
Network Analysis refers to the methods and techniques used to study and evaluate networks. It involves identifying patterns, measuring node importance, analyzing connectivity, and understanding the underlying structure and function of the network.
When and With Which Type of Data is Network Analysis Useful?
Network analysis is particularly useful when the data can be
represented as relationships or interactions between entities. Any type
of data with this quality can be transformed into network data. Network
data is nothing but a tabular dataset with at least two columns: a
source column and a target column. Each of
these columns contains the names of the entities that are connected to
each other in the network. Other columns can contain more information
about the connection between source and
target, including the weight of this connection
(identifying how strong it is) or its type (for example, whether it is a
connection between a human and a work of art, or one between two
humans).
In a visualized network, the sources and targets (usually represented
by dots in the graph) are called nodes, and the lines
connecting them are called edges.
Major Types of Networks
There are many different network types. Familiarity with them helps you decide in the future, when working with your own data, what network type your data can be converted to in order to optimally analyze its different features.
Some important network types include:
1. Directed vs. Undirected Networks
Directed Networks: In these networks, the edges have a direction, indicating a one-way relationship between nodes. For example, in a citation network, if Paper A cites Paper B, the link goes from A to B but not necessarily in the reverse direction.
Undirected Networks: Here, the edges do not have a direction, representing a symmetric relationship. An example would be a friendship network where two people are friends with each other, and the relationship is mutual.
2. Weighted vs. Unweighted Networks
Weighted Networks: In weighted networks, edges have weights assigned to them, indicating the strength or capacity of the relationship. For instance, in a transportation network, the weights could represent distances or travel times.
Unweighted Networks: These networks have edges that are simply present or absent, with no additional information about the strength of connections. An example is a simple social network where the only consideration is whether or not a connection exists.
3. Bipartite Networks
Bipartite networks consist of two distinct sets of nodes, and edges only connect nodes from different sets. An example is a movie recommendation system, where one set consists of users and the other set consists of movies.
4. Homogeneous vs. Heterogeneous Networks
Homogeneous Networks: These networks consist of nodes of the same type. An example is a social network where all nodes represent people.
Heterogeneous Networks: In these networks, nodes can represent different types of entities. For instance, a scientific citation network can include papers, authors, and journals as different types of nodes.
2. Visualizing Network Data
As mentioned above, network data is a specific form of tabular data. For the analyses in this lesson, I have extracted some network data from the website of Wikidata, using the programming language SPARQL. For this lesson, it is not necessary to understand how SPARQL works.
The dataset is stored in a CSV file. It represents a table composed
of two columns: source and target. Both
columns contain names of mostly European personalities. This table was
constructed to represent a directional network, meaning that the
philosophers and thinkers that appear in the source column
have influenced the work of those in the target column.
To construct this dataset, I have searched Wikidata for people whose work has been influenced by Karl Marx, Georg Wilhelm Friedrich Hegel, Immanuel Kant, Benedictus de Spinoza, René Descartes, Plato, or Aristotle, as well as those who have influenced the work of these philosophers. Therefore, these seven personalities make up the most important nodes in the network.
Let’s read the data into Jupyter Notebook, convert it to a Pandas dataframe, and display a sample of that dataframe with ten rows:
PYTHON
import pandas as pd
data_url='https://raw.githubusercontent.com/HERMES-DKZ/python_101_humanities/main/episodes/data/influence_network.csv'
influence_df = pd.read_csv(data_url)
influence_df.sample(10)
Now let’s write some Python code that visualizes the network graph for us:
PYTHON
import networkx as nx
from pyvis.network import Network
# Step 1: Build the NetworkX graph
G = nx.DiGraph()
# Add nodes
all_nodes = set(influence_df['source']).union(set(influence_df['target']))
G.add_nodes_from(all_nodes)
# Add edges
for _, row in influence_df.iterrows():
G.add_edge(row['source'], row['target'])
# Step 2: Create a PyVis network
net = Network(directed=True, height='1000px', width='100%')
# Import the NetworkX graph
net.from_nx(G)
# Step 3: Apply your original visual styling
highlighted = {
'Karl Marx',
'Georg Wilhelm Friedrich Hegel',
'Immanuel Kant',
'Benedictus de Spinoza',
'René Descartes',
'Plato',
'Aristotle'
}
for node in net.nodes:
if node['id'] in highlighted:
node['color'] = 'orangered'
else:
node['color'] = 'slategrey'
for edge in net.edges:
edge['color'] = 'darkseagreen'
edge['arrows'] = 'to'
# Step 4: Save output
net.save_graph("influence_network.html")
print("FINISHED! Network saved as 'influence_network.html'.")
Don’t worry if the network that you have visualized in your code
doesn’t look exactly like the one displayed here. Pyvis
creates interactive network graphs, so that you can pull the nodes
around with the mouse and change their constellation.
Let’s analyze the code line by line
First, let’s look at what is happening at each step:
- Build the
NetworkXgraph: Creates a directed graphG, collects unique node names frominfluence_df, and adds directed edges from source → target. - Create a
PyVisnetwork: Builds an interactive visualization object net (browser-friendly) and imports theNetworkXgraph into it. - Apply visual styling: Colors a chosen set of important nodes (highlighted) differently, sets a color and arrow style for every edge.
- Save output: Writes the interactive HTML file
influence_network.htmland prints a short completion message.
Now, let’s look more deeply into what each code chunk does:
import networkx as nx
from pyvis.network import NetworkImports the NetworkX library under the name
nx — used for building and manipulating graphs. Imports
Network from PyVis, a class for creating
interactive network visualizations that open in a browser.
# Step 1: Build the NetworkX graph
G = nx.DiGraph()Creates an empty directed graph object G (edges have
direction).
# Add nodes
all_nodes = set(influence_df['source']).union(set(influence_df['target']))Collects all unique node names: takes the source column
and target column from influence_df, converts
each to a set, and unions them so each node appears once.
G.add_nodes_from(all_nodes)Adds every element of all_nodes as a node in the graph
G.
# Add edges
for _, row in influence_df.iterrows():
G.add_edge(row['source'], row['target'])Loops over each row of influence_df. For each row, reads
source and target and adds a directed edge from source to
target in G. (_ ignores the row index returned
by iterrows().)
# Step 2: Create a PyVis network
net = Network(directed=True, height='1000px', width='100%')Creates a PyVis Network instance net.
directed=True ensures arrows are shown for direction;
height/width set how big the visualization will appear in the
browser.
# Import the NetworkX graph
net.from_nx(G)Converts the NetworkX graph G into the
PyVis object net, copying nodes and edges so
PyVis can render them interactively.
# Step 3: Apply your original visual styling
highlighted = {
'Karl Marx',
'Georg Wilhelm Friedrich Hegel',
'Immanuel Kant',
'Benedictus de Spinoza',
'René Descartes',
'Plato',
'Aristotle'
}Defines a Python set named highlighted
containing node labels that should receive special visual styling (these
are the seven featured philosophers mentioned earlier).
for node in net.nodes:
if node['id'] in highlighted:
node['color'] = 'orangered'
else:
node['color'] = 'slategrey'Iterates each node in the PyVis representation. In
PyVis, each item in net.nodes is a dictionary
describing one visual node in the interactive network. It contains all
the display attributes PyVis needs to render that node in
the browser. Each dictionary represents one node in your network,
including: - the node’s internal ID (usually the label from the NetworkX
graph) - the text shown next to the node - visual settings such as size,
color, shape, and physics behavior
In each iteration, if the node’s id (its label) is in
highlighted, sets its color to ‘orangered’, otherwise sets
it to ‘slategrey’. This changes node appearance in the HTML output.
for edge in net.edges:
edge['color'] = 'darkseagreen'
edge['arrows'] = 'to'Iterates every edge (each is a dictionary, similar to
net.nodes). Sets the edge color to ‘darkseagreen’ and
ensures an arrowhead points from source to target by setting ‘arrows’ to
‘to’.
# Step 4: Save output
net.save_graph("influence_network.html")Writes the interactive visualization to the file
influence_network.html. Opening that file in a browser
shows the network with the applied styling.
Visualizing network data is very helpful, because it helps you understand the dataset better and decide what insights it can offer you in your research.
Challenge
Study the visualized graph more closely. This is a directional graph of influence in the realm of European philosophy. With a partner, discuss what questions the visualized dataset can answer. These questions guide the further analytic actions that we will undertake in this lesson.
Below are some of the questions that we could answer using this dataset:
- Among the seven highlighted thinkers based on whom the dataset has been curated, which one has been more influential? Which one has had the least among of influence?
- Which thinkers have been influenced by the largest number of the highlighted thinkers?
- How can the influence of the highlighted thinkers be quantitatively measured?
In the following sections, we will answer the questions above using different network analysis techniques.
3. Measuring the out-degree
The out-degree of a node is the number of arrows going out from that node. In our influence graph, if a philosopher is connected to many others with arrows pointing from them to others, that means they influenced many people. So:
out-degree = how many people a thinker influenced (according to our dataset).
Let’s write a python code that calculates the out-degree of the highlighted seven thinkers:
PYTHON
# List of highlighted thinkers
highlighted = [
'Karl Marx',
'Georg Wilhelm Friedrich Hegel',
'Immanuel Kant',
'Benedictus de Spinoza',
'René Descartes',
'Plato',
'Aristotle'
]
# Compute integer out-degree safely
influence_counts = {}
for thinker in highlighted:
influence_counts[thinker] = int(G.out_degree(thinker))
# Identify most and least influential
most_influential = max(influence_counts, key=lambda k: influence_counts[k])
least_influential = min(influence_counts, key=lambda k: influence_counts[k])
print("Influence counts among highlighted thinkers:")
for k, v in influence_counts.items():
print(f"{k}: {v}")
print("\nMost influential thinker:", most_influential)
print("Least influential thinker:", least_influential)
Let’s analyze the code line by line
highlighted = [
'Karl Marx',
'Georg Wilhelm Friedrich Hegel',
'Immanuel Kant',
'Benedictus de Spinoza',
'René Descartes',
'Plato',
'Aristotle'
]This line re-defines the highlighted list from the
previous code chunk. The list will be used to loop through these
thinkers later.
influence_counts = {}This line creates an empty dictionary called
influence_counts.
for thinker in highlighted:
influence_counts[thinker] = int(G.out_degree(thinker))These lines create a For loop. The loop goes through the
highlighted list one thinker at a time. During each cycle,
the variable thinker holds one name from the list.
influence_counts[thinker] = int(G.out_degree(thinker))
retrieves the thinker’s out-degree from the graph G.
G.out_degree(thinker) returns how many edges point
outward from that thinker.
int(...) ensures that the result is stored as a plain
integer.
The dictionary influence_counts stores this value under
the thinker’s name.
most_influential = max(influence_counts, key=lambda k: influence_counts[k])This line finds the thinker with the highest out-degree.
max(...) selects the key (the thinker) whose value in the
dictionary is largest.
key=lambda k: influence_counts[k] uses a lambda function
that tells Python to compare items based on their stored influence
number.
A lambda function in Python is a very small, short function that you create without giving it a name. Because it has no name, it is called an anonymous function.
It is used when you need a simple function for a short amount of time
and do not want to write a full function with def.
A simple lambda function looks like this:
lambda x: x + 1This means:
- take an input called x
- return x + 1
So if you used it like this:
f = lambda x: x + 1then f(5) would return 6.
In our code, we have:
key=lambda k: influence_counts[k]This means:
- Python is given a tiny function
- The function takes one input,
k - The function returns `influence_counts[k]```
In other words, when Python tries to find the maximum value in the dictionary, it uses the lambda function to tell it: “Look up the value for each thinker and compare those values.”
least_influential = min(influence_counts, key=lambda k: influence_counts[k])This line works the same way as the previous one, but uses
min(...) to find the smallest out-degree. The result is the
thinker who influenced the fewest people in the dataset.
Finally, the last code lines implement functions that you have already learned in the previoius episodes.
So far, we know that Karl Marx has been the most influential among the highlighted personalities in our dataset, whereas the least influential person has been René Descartes. Let’s draw a bar chart to better understand the out-degrees of the seven selected nodes, which gives us a measure of how influential they have been in the world of philosophy and literature.
PYTHON
import plotly.express as px
# Sort philosophers by out-degree (highest → lowest)
sorted_items = sorted(influence_counts.items(), key=lambda x: x[1], reverse=True)
# Unpack the sorted items back into two lists
philosophers = [item[0] for item in sorted_items]
out_degrees = [item[1] for item in sorted_items]
# Create bar plot
fig = px.bar(
x=philosophers,
y=out_degrees,
labels={'x': 'Philosopher', 'y': 'Out-degree'},
title='Out-degree (Influence Count) of Highlighted Philosophers'
)
fig.show()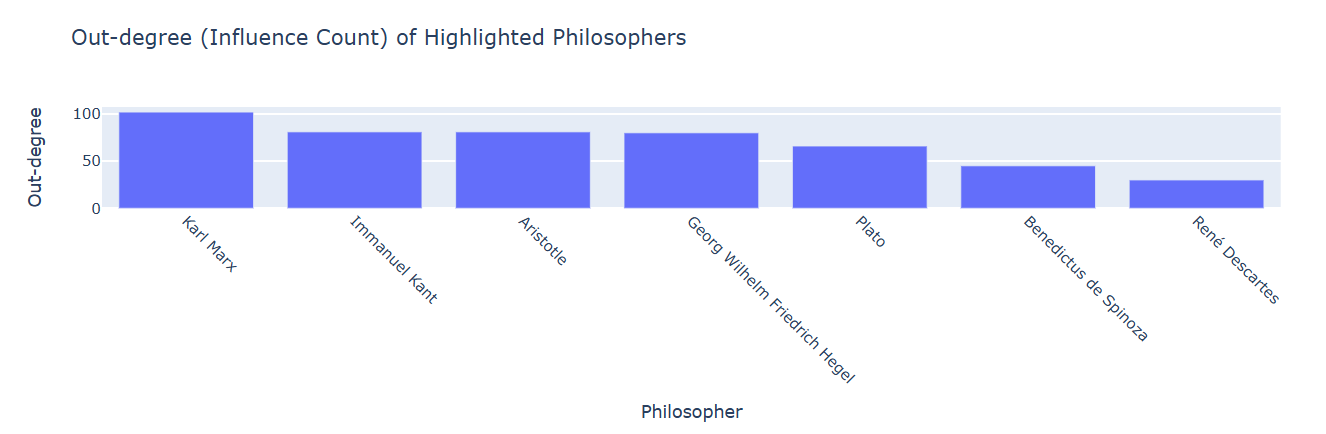
In the above code, only the few first lines merit a brief explanation.
Let’s analyze a few code lines
sorted_items = sorted(influence_counts.items(), key=lambda x: x[1], reverse=True)influence_counts.items() produces all key–value pairs
from the dictionary. Each item looks like: (‘Plato’, 9) or (‘Aristotle’,
6).
sorted(..., key=lambda x: x[1], reverse=True) Sorts
those key–value pairs based on the value (the out-degree).
x represents one pair, such as (‘Plato’, 9).
x[1] selects the second part of the pair, the
out-degree.
reverse=True makes the list sorted from highest to
lowest.
The result, stored in sorted_items, is a list of tuples
ordered by out-degree.
philosophers = [item[0] for item in sorted_items]This creates a new list containing only the names of the
philosophers, in the sorted order. item[0] means “take the
first part of each tuple,” which is the philosopher’s name.
out_degrees = [item[1] for item in sorted_items]This creates another list containing only the out-degree numbers, in
the same sorted order. item[1] means “take the second part
of each tuple,” which is the out-degree.
4. Measuring the in-degree
In the previous section, we measured the out-degrees. In this one, we want to measure the in-degrees to see which thinkers have been influenced by the largest number of the highlighted thinkers, which translates into: which nodes have the highest number of arrows pointing at them. We count, for each node, how many of its incoming edges come from the highlighted thinkers.
Let’s write a Python code that performs the in-degree count for us:
PYTHON
# Step 1: Create a dictionary to count influences from highlighted thinkers
influence_count = {node: 0 for node in G.nodes}
# Step 2: Count how many highlighted thinkers influence each node
for target in G.nodes:
predecessors = set(G.predecessors(target)) # thinkers influencing this target
influence_count[target] = len(predecessors.intersection(highlighted))
# Step 3: Find the maximum count
max_influence = max(influence_count.values())
# Step 4: Find the non-highlighted thinkers influenced by the maximum number of highlighted thinkers
most_influenced_thinkers = [
node for node, count in influence_count.items()
if count == max_influence and node not in highlighted
]
print("Thinkers influenced by the maximum number of highlighted thinkers:", most_influenced_thinkers)
print("Number of highlighted thinkers influencing them:", max_influence)
Let’s analyze the code line by line
influence_count = {node: 0 for node in G.nodes}G.nodes gives a list of all thinkers (nodes) in the
network.
{node: 0 for node in G.nodes} is a dictionary
comprehension. It creates a dictionary where each thinker starts with a
count of 0, meaning initially we assume no highlighted thinkers
influence them.
for target in G.nodes:
predecessors = set(G.predecessors(target)) # thinkers influencing this target
influence_count[target] = len(predecessors.intersection(highlighted))for target in G.nodes: loops over every thinker in the
network.
G.predecessors(target) gives a list of thinkers who have
an arrow pointing to this thinker — in other words, thinkers who
influenced them.
set(predecessors) converts the list of influencers into
a set for easy comparison.
predecessors.intersection(highlighted) finds which of
the influencers are in our highlighted thinkers set.
len(...) counts how many highlighted thinkers influence
this node.
influence_count[target] = ... updates the dictionary
with this number.
max_influence = max(influence_count.values())influence_count.values() gives all the counts of
highlighted thinkers for each node.
max(...) finds the largest number, i.e., the highest
number of highlighted thinkers influencing a single thinker.
most_influenced_thinkers = [
node for node, count in influence_count.items()
if count == max_influence and node not in highlighted
]The list comprehension
[node for node, count in ... if count == max_influence and node not in highlighted]
creates a list of thinkers whose count equals the maximum. It also makes
sure that the nodes in this list, whose in-degrees are being measured,
do not belong to the highlighted list.
The thinkers in the list most_influenced_thinkers are
those influenced by the highest number of highlighted thinkers.
Wonderful! We now know that Michel Foucault, Alain, and Evald Ilyenkov have taken the greatest influence from the highlighted thinkers. Let’s now create a filtered network dataset, consisting only of these three nodes and the seven highlighted thinkers, and visualize it. This visualization should give us a better understanding of European philosophy’s landscape concerning the seven highlighted thinkers:
PYTHON
import pandas as pd
import networkx as nx
from pyvis.network import Network
# Combine nodes to include in the smaller network
nodes_to_include = highlighted.union(most_influenced_thinkers)
# Step 1: Build the filtered NetworkX graph
G_filtered = nx.DiGraph()
# Add only the relevant nodes
G_filtered.add_nodes_from(nodes_to_include)
# Add edges only if both source and target are in nodes_to_include
for _, row in influence_df.iterrows():
if row['source'] in nodes_to_include and row['target'] in nodes_to_include:
G_filtered.add_edge(row['source'], row['target'])
# Step 2: Create a PyVis network
net = Network(directed=True, height='1000px', width='100%')
# Import the filtered NetworkX graph
net.from_nx(G_filtered)
# Step 3: Apply the same visual styling
for node in net.nodes:
if node['id'] in highlighted:
node['color'] = 'orangered'
else:
node['color'] = 'slategrey'
for edge in net.edges:
edge['color'] = 'darkseagreen'
edge['arrows'] = 'to'
# Step 4: Save the filtered network
net.save_graph("filtered_influence_network.html")
print("FINISHED! Filtered network saved as 'filtered_influence_network.html'.")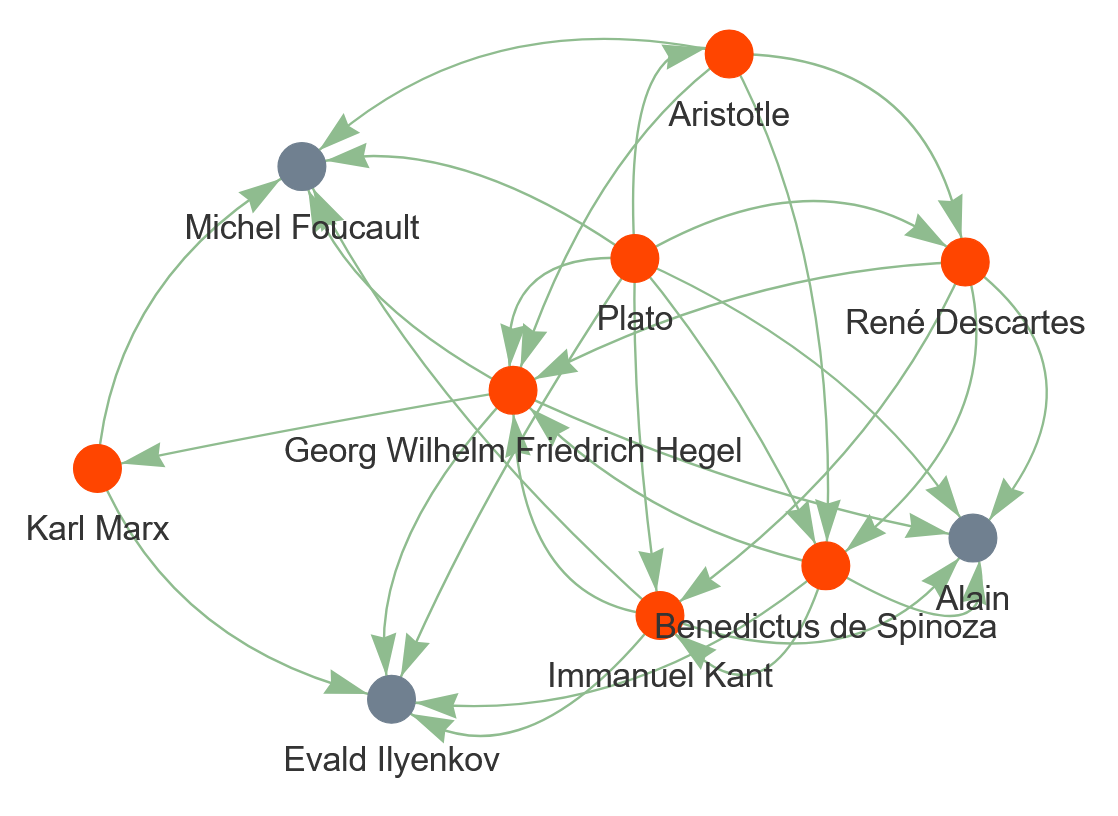
With a peer, study the visualized graph carefully and discuss what information it provides about European philosophy.
5. Measuring centrality degrees
Finally in this episode, let’s answer the third question we stated above: How can the influence of the highlighted thinkers be quantitatively measured? To do so, we can measure three so-called centrality degrees for the nodes in the highlighted list. These are:
- Degree Centrality
- Betweenness Centrality
- Closeness Centrality
Degree Centrality
Definition:
- Measures the number of direct connections a node has to other nodes.
- In a directed graph, degree centrality usually counts both incoming and outgoing edges unless specifically split into in-degree and out-degree centrality.
Why we measure it:
- It shows how “connected” a node is in the network.
- In a social or influence network, a thinker with a high degree centrality either influences many thinkers (high out-degree) or is influenced by many thinkers (high in-degree).
- It is a simple and intuitive measure of a node’s importance in terms of direct connections.
Unit and Range:
- Normalized unitless number that ranges from 0 to 1:
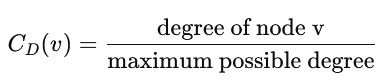
- 0 means no connections, 1 means connected to all other nodes in the network.
Betweenness Centrality
Definition:
- Measures how often a node lies on the shortest paths between other pairs of nodes.
- A node with high betweenness acts as a “bridge” or bottleneck connecting different parts of the network.
Why we measure it:
- Identifies thinkers who are key intermediaries.
- Even if a thinker is not highly connected (low degree), they may control the flow of influence in the network if many shortest paths pass through them.
Unit and Range:
- Normalized unitless number that ranges from 0 to 1:
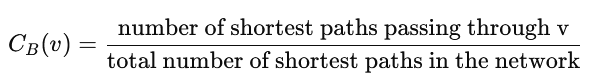
- 0 means the node is never on a shortest path between any two other nodes.
- 1 means the node is on all shortest paths (rare in real networks).
Closeness Centrality
Definition:
- Measures how close a node is to all other nodes in the network, based on the shortest paths.
- High closeness means a node can quickly interact with (or influence) all other nodes.
Why we measure it:
- Shows which thinkers are “centrally located” in the network.
- A thinker with high closeness can reach many others efficiently, making them influential even without high degree or betweenness.
Unit and Range:
- Normalized unitless number that ranges from 0 to 1:

- 0 means the node is very far from others (or disconnected).
- 1 means the node is as close as possible to all others (rare).
At this stage, you should be at a point where you can understand the following code without any explanation. Congratulations! You’re becoming a profi in Python programming!
Now that you know what information these centrality degrees reveal, let’s measure them for the nodes in the list of highlighted thinkers.
PYTHON
import pandas as pd
# Step 1: Calculate centralities
degree_centrality = nx.degree_centrality(G)
betweenness_centrality = nx.betweenness_centrality(G)
closeness_centrality = nx.closeness_centrality(G)
# Step 2: Collect centralities only for highlighted thinkers
data = []
for node in highlighted:
data.append({
'Thinker': node,
'Degree Centrality': round (degree_centrality[node], 2),
'Betweenness Centrality': round (betweenness_centrality[node], 2),
'Closeness Centrality': round (closeness_centrality[node], 2)
})
# Step 3: Create a pandas DataFrame
centrality_df = pd.DataFrame(data)
# Step 4: Sort by Degree Centrality (optional)
centrality_df = centrality_df.sort_values(by='Degree Centrality', ascending=False).reset_index(drop=True)
centrality_df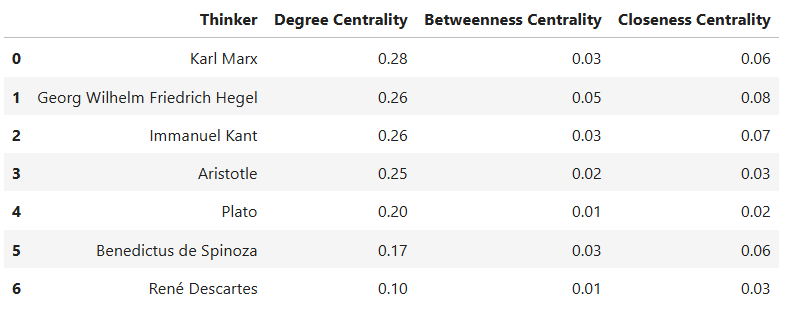
To develop a better understanding of the degree centralities in the dataframe, let’s visualize them in a stacked bar chart:
PYTHON
# Step 1: Transform the DataFrame to long format
centrality_long = centrality_df.melt(
id_vars='Thinker',
value_vars=['Degree Centrality', 'Betweenness Centrality', 'Closeness Centrality'],
var_name='Centrality',
value_name='Value'
)
# Step 2: Create a grouped bar chart with text above the bars
fig = px.bar(
centrality_long,
x='Thinker',
y='Value',
color='Centrality',
barmode='group',
text='Value', # Show numeric values
title='Comparison of Centralities for Highlighted Thinkers',
height=700
)
# Step 3: Ensure all text values are horizontally above the bars
fig.update_traces(textposition='outside') # Forces all values above bars
# Step 4: Customize layout
fig.update_layout(
xaxis_title='Thinker',
yaxis_title='Centrality (normalized 0-1)',
legend_title='Centrality Measure',
yaxis=dict(range=[0, 1]),
template='plotly_white'
)
# Step 5: Show figure
fig.show()
Now that you know what each centrality degree means and you have the measures and graphs regarding the centrality degrees of the seven highlighted thinkers in the network data, discuss with a partner:
- What do these measures mean for the seven selected thinkers?
- Which thinker among the highlighted ones has the highest number of connections?
- Which thinker has most effectively served as a bridge between other thinkers in the network data?
- Which thinker has likely most influenced or been influenced by others in the network?
- Understand the use cases of network analysis.
- Visualize networks using the Python library Pyvis.